

The Era of Distributed AI Risk
If you are building systems that integrate AI today, you have probably felt a growing sense of uncertainty. Not because AI itself is hard to use, but because the ecosystem around it is expanding faster than most teams can safely manage. Every new framework, SDK, or orchestration layer introduces power, but also introduces more things that can go wrong.
Teams working with Go and AI often ask the same questions. How secure are the tools we are using? Who is responsible when something breaks in the dependency chain? And more importantly, how do we even begin to assess risk in systems that rely on dozens of external components? These are no longer theoretical concerns, they are becoming daily engineering realities.
A recent security incident involving the AI tooling ecosystem around LiteLLM highlights this shift clearly. It is not just about one vulnerable package or one misconfiguration. It is about how AI systems today are built on top of deep dependency trees that extend far beyond application code. As AI adoption accelerates across Go-based backend systems, understanding these risks is becoming essential for any engineering team building production-grade AI.
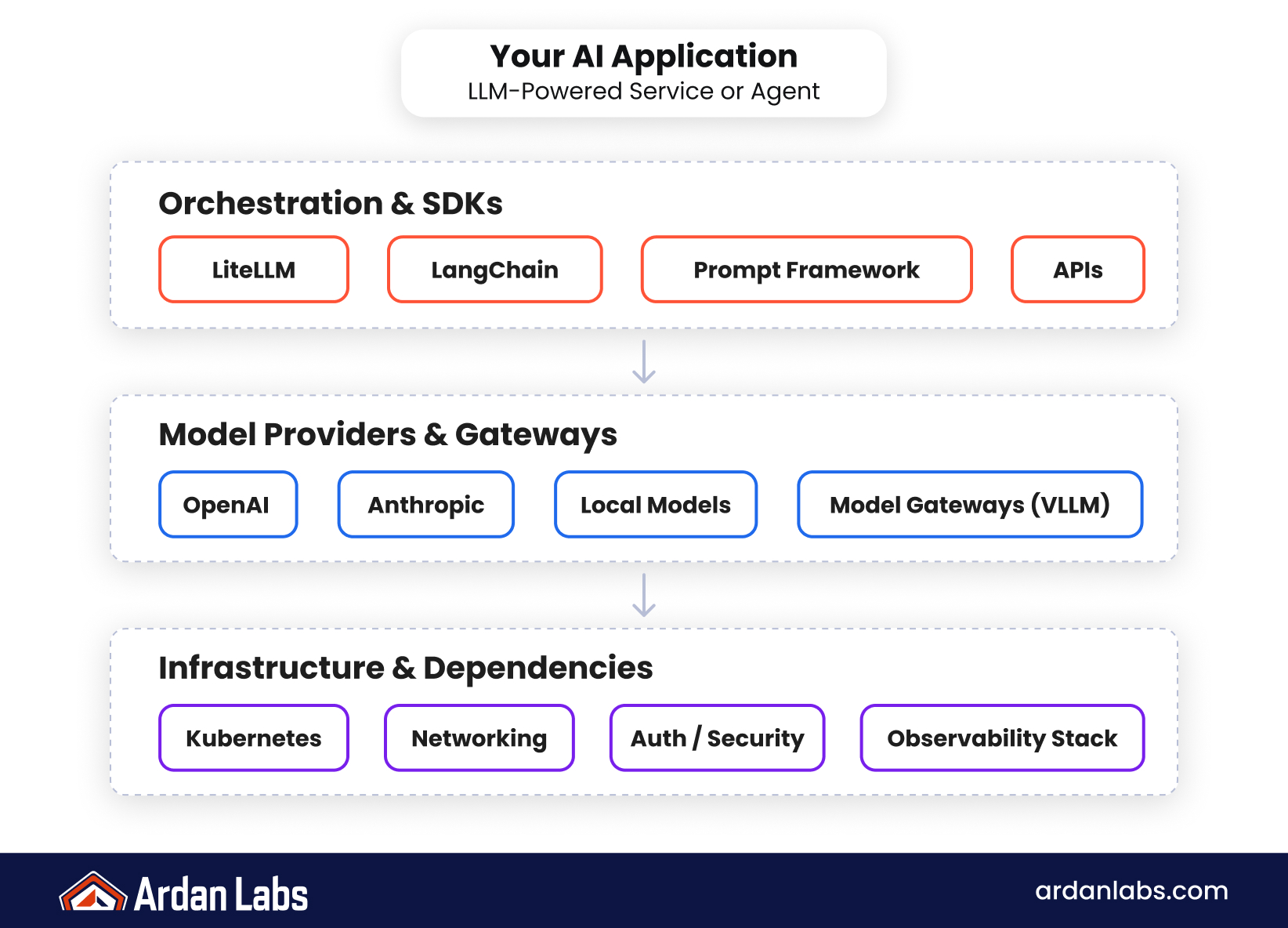
AI Systems Are Now Defined by Their Dependency Chains
Modern AI applications are rarely standalone systems. They are composed of APIs, orchestration layers, SDKs, model gateways, and infrastructure wrappers that all interact in real time. This means that the security of the system is no longer defined by a single codebase, but by the combined trustworthiness of every dependency it relies on.
The LiteLLM-related incident is a signal of this new reality. When vulnerabilities appear in upstream tooling, the impact is no longer isolated. It can cascade into production environments that rely on these abstractions to connect models, routes, and execution pipelines. This creates a situation where even well-designed Go services can inherit risk from components they do not directly control.
Key implications for engineering teams include:
- Increased reliance on third-party AI orchestration tools
- Expanded attack surface across API and model layers
- Reduced visibility into transitive dependencies
- Higher operational risk in production AI workloads
- Difficulty auditing end-to-end system behavior
When teams assume that AI tooling is “just another library,” they underestimate the systemic nature of these dependencies. In practice, AI systems behave more like ecosystems than applications, and ecosystems are harder to secure, monitor, and reason about.
The takeaway is simple but critical: in AI-driven architectures, security is no longer local to your service. It is distributed across everything your system touches.
Why Traditional Software Security Models Are Struggling
Most engineering teams still apply traditional software security thinking to AI systems. That model assumes clear boundaries, predictable execution paths, and stable dependencies. However, AI systems break many of these assumptions by design. They dynamically call external services, route requests through orchestration layers, and often rely on evolving model behaviors.
This creates a mismatch between how systems are built and how they are secured. In Go-based backend systems, this is especially visible when AI services are integrated as external dependencies. The application may be stable, but the AI layer introduces variability that traditional security models are not designed to handle.
Consider how this shifts operational thinking:
- Security reviews now need to include AI toolchains, not just application code
- Dependency updates can introduce behavioral changes, not just bug fixes
- Observability must extend into AI routing and orchestration layers
- Incident response must account for external model and API behavior
- Risk assessment must include supply chain trust, not just code quality
As one security engineer recently summarized in a public discussion on AI infrastructure risk, “We are no longer securing applications, we are securing networks of trust we barely understand.”
This is particularly relevant for Go teams building backend systems that interact with AI APIs or frameworks. The language itself is not the issue, it is the architecture around it. Go provides strong concurrency and reliability, but it cannot compensate for insecure or opaque dependencies upstream.
The key insight is that traditional security models are still necessary, but no longer sufficient. AI systems require a broader view of trust, one that includes the entire supply chain.
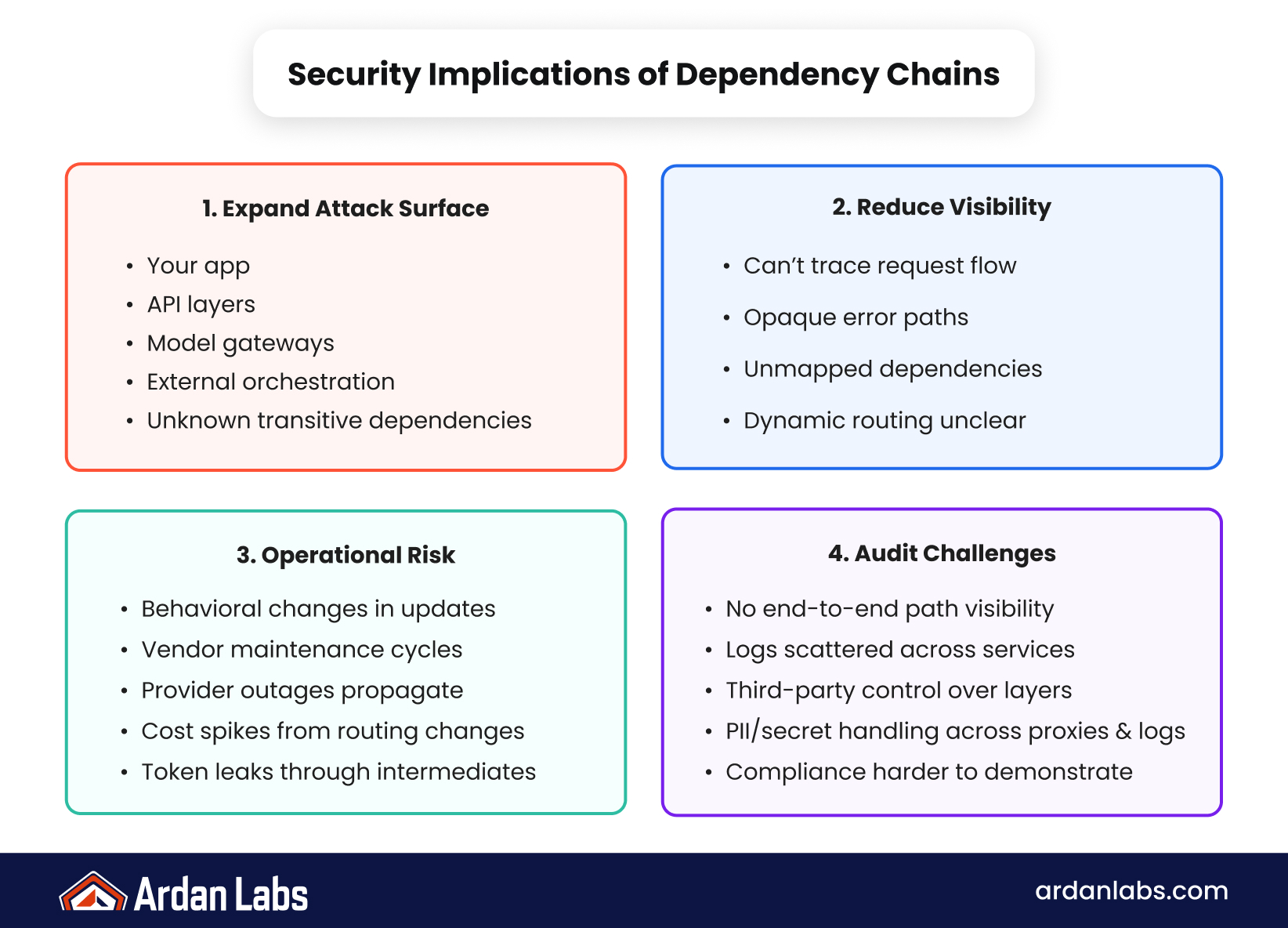
The Hidden Risk: Abstraction Layers in AI Tooling
One of the most overlooked risks in modern AI systems is the abstraction layer problem. Tools like AI gateways, model routers, and orchestration frameworks simplify development, but they also hide complexity that teams often fail to fully understand.
These abstraction layers act as intermediaries between your application and the model providers. While this improves developer experience, it also introduces blind spots. When something goes wrong, it is often unclear whether the issue originates in your Go service, the orchestration layer, or the upstream model provider.
The LiteLLM ecosystem highlights this challenge. By abstracting model routing and API interactions, it enables faster development cycles. However, it also creates a dependency chain where a single vulnerability or misconfiguration can propagate across multiple layers of production systems.
This introduces several practical risks:
- Reduced transparency into request and response flows
- Difficulty tracing security incidents across layers
- Increased reliance on third-party maintenance cycles
- Potential exposure of sensitive data through intermediate services
- Challenges in enforcing consistent security policies
The deeper issue is not the existence of abstraction layers, but the assumption that abstraction equals safety. In reality, abstraction often shifts complexity rather than removing it. For teams working with Go and AI, this means rethinking where control and visibility actually reside in the system.
Understanding these layers is critical for building resilient AI systems. Without this understanding, teams risk inheriting vulnerabilities they cannot easily detect or resolve.

Rethinking AI Security as an Ecosystem Problem
The shift we are seeing is not just technical, it is structural. AI systems are evolving into interconnected ecosystems where models, tools, APIs, and infrastructure all depend on each other in real time. Security in this context cannot be treated as a single layer of defense.
Instead, teams need to think in terms of ecosystem resilience. This means understanding not only how each component behaves, but how they interact under stress, failure, or compromise.
A more effective approach includes:
- Dependency mapping across AI workflows, including transitive packages and hosted services — not only the libraries in the application repo
- End-to-end observability across gateway and orchestrator routing, provider errors and latency, token and cost spikes, and sensitive data in requests and responses (this is still API traffic — instrument it with those dimensions in mind)
- Regression testing for AI tooling and provider upgrades, treating behavior drift as a first-class change, not an afterthought
- Degradation design for when external AI is down, overloaded, or misbehaving: timeouts, quotas, backpressure, and safe fallbacks
- Orchestration treated as critical infrastructure — same ownership, change control, and incident rigor as core APIs, not a side utility
The focus is shifting from “Is this component secure?” to “What happens when any part of this system behaves unexpectedly?”
The key insight is that AI security is no longer about hardening a single application. It is about understanding and managing a distributed system of trust.
Practical Strategies for Engineering Teams
Teams building Go-based AI systems can start addressing these risks without overhauling their entire architecture. The goal is not to eliminate complexity, but to make it visible and manageable.
First, boundaries. Draw a clear line between core Go services and AI-adjacent components. Treat gateways and orchestration as external infrastructure with explicit interfaces, not as invisible helpers inside the application. That isolates risk and improves observability.
Second, operationalize dependency awareness. Assign ownership of the dependency inventory to a specific team or engineer. Roll out upgrades in stages when the AI stack changes. Prefer structured, redacted request metadata for traceability and audits—enough to respond to incidents—rather than logging full prompts by default.
Finally, assume failure. External AI will change, degrade, or misbehave. Design for timeouts, backpressure, and degradation paths. That is operational realism, not pessimism; in production, providers and tooling will keep moving and will sometimes introduce risk.

Recognizing the Structural Shift:
Building Resilient AI Systems in an Interconnected World
The LiteLLM-related security signals are not isolated events. They are part of a broader shift in how AI systems are built, deployed, and secured. As AI becomes deeply embedded in backend systems, especially those built with Go, the traditional boundaries of security are being redefined.
Teams that recognize this shift early will be better positioned to build systems that are not only functional but resilient. If these challenges resonate with your team, exploring guidance from experienced engineering teams, like those at Ardan Labs, can provide practical ideas and support to navigate the growing complexity of AI system design and security.
Reference
For more details on the incident referenced in this article, see LiteLLM’s security update: Security Update — March 2026.
Frequently Asked Questions
LiteLLM is commonly used as an LLM gateway or proxy layer that standardizes how applications call multiple model providers. It can speed integration and routing, but it also becomes a critical dependency in your AI supply chain.
An LLM gateway sits between your services and model providers to handle routing, auth, logging, and policy. It increases the attack surface and can obscure data flows, so failures or misconfigurations can affect every downstream application.
Modern AI stacks combine APIs, orchestration, SDKs, model gateways, and hosted services. Production security depends on the trustworthiness of that whole graph, including transitive dependencies, not only the code in your repository.
It shows how an LLM gateway or orchestration layer can concentrate risk. A single weak link, vulnerability, or misconfiguration can propagate across routing, policy, and execution layers that many production services depend on.
Security is distributed across everything the system touches: gateways, orchestration, model and API layers, and infrastructure wrappers. That means a wider attack surface and harder end-to-end auditing than many traditional application designs.
Gateways, routers, and orchestration frameworks speed development but hide complexity. When something fails, it can be unclear whether the root cause is your service, the gateway, or the upstream provider, and sensitive data may traverse intermediaries you only partially control.
Usually not. AI stacks behave more like ecosystems: many moving parts, evolving behavior, and cross-layer failure modes that are harder to secure, monitor, and reason about than a conventional dependency.
It means prioritizing resilience across the whole workflow: mapping dependencies (including transitive and hosted services), observing gateway and orchestrator routing, regression-testing upgrades for behavior drift, and designing safe degradation when external AI fails.
Separate core services from AI tooling, treat gateways and orchestration as external infrastructure, stage upgrades, prefer structured redacted metadata over logging full prompts, and design for timeouts, quotas, backpressure, and safe fallbacks.
Extend observability through the AI path: gateway routing, provider errors and latency, token and cost spikes, and how sensitive data appears in requests and responses.


