

Kubernetes CPU limits can look straightforward on the surface, but their impact on application performance is anything but simple. This article unpacks how Go services interact with Kubernetes CPU throttling and why a seemingly harmless configuration such as setting a limit of 250m can dramatically constrain performance in production. First published in February 2024, its insights remain just as relevant today for anyone running Go applications in containerized environments and for developers who want to avoid costly slowdowns.
Introduction
I was working on a Go service that was going to be deployed into a managed Kubernetes (K8s) environment on GCP. One day I wanted to look at the logs in the staging environment and got access to the ArgoCD platform. In the process of trying to find the logs, I stumbled upon the YAML that described the deployment configuration for my service. I was shocked to see that the CPU limit was set to 250m. I had a cursory understanding that it meant my service would be limited to 25% of a CPU, but I honestly had no clue what it really meant.
I decided to reach out to the OPS team and ask them why that number of 250m was being set and what it meant? I was told that this is a default value set by Google, they don’t touch it, and in their experience, the setting didn’t seem to cause problems. However, they didn’t understand the setting anymore than I did. That wasn’t good enough for me and I wanted to understand how the setting would affect my Go service running in K8s. That started an intense 2 day exploration and what I found was super interesting.
I believe there are many Go services running in K8s under CPU limits that are not running as efficiently as they otherwise could be. In this post, I will explain what I learned and show what happens when CPU limits are being used and your Go service isn’t configured to run within the scope of that setting.
K8s CPU Limits
This is what I saw in the deployment YAML for my service that started this whole journey.
Listing 1
containers:
- name: my-service
resources:
requests:
cpu: "250m"
limits:
cpu: "250m"
You can see a CPU limit of 250m being set. The CPU limit and request value are configured in a unit called millicores. A millicore allows you to describe fractions of CPU time. As an example, if you want to configure a service to use 100% of a single CPU’s time, you would use a millicore value of 1000m. The millicore value of 250m means the service is limited to 25% of a single CPU’s time.
The mechanics behind giving a service some percentage of time on a CPU can vary between architectures and operating systems, so I won’t go down that rabbit hole. I will focus on the semantics since it will model the behavior you will experience.
To keep things simple to start, imagine a K8s cluster that has a single node with only 1 CPU.
Figure 1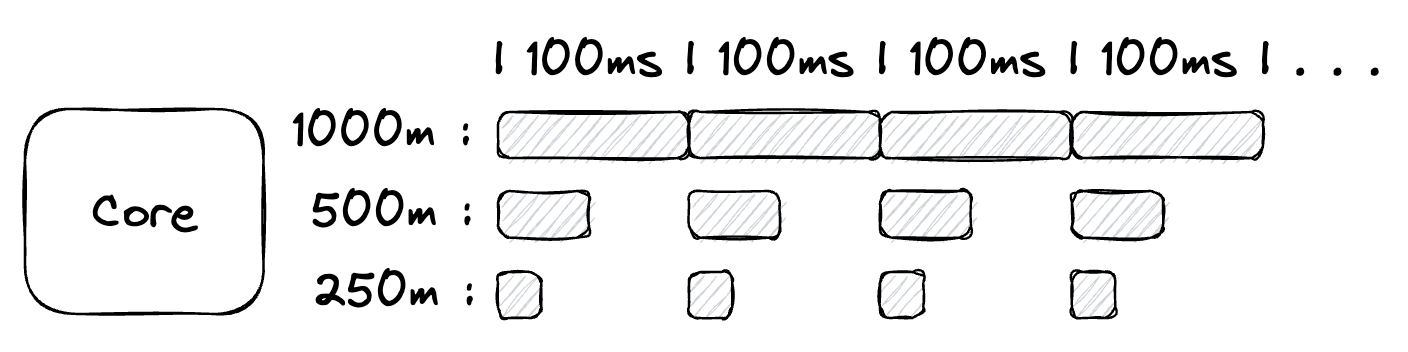
Figure 1 represents a node with a single CPU. For this single CPU, K8s starts a 100 millisecond cycle that repeats over and over again. On each cycle, K8s shares the 100 milliseconds of time between all the services running on the node proportional to how that time is assigned under the CPU limit setting.
If there was just one service running on the node, then you could assign that service all 100ms of time for each cycle. To configure that, you would set the limit to 1000m. If two services were running on the node, you might want those services to equally share the CPU. In this case, you would assign each service 500m, which gives each service 50ms of time on every 100ms cycle. If four services were running on the node, you could assign each service 250m, giving each service 25ms of time on every 100ms cycle.
You don’t have to assign the CPU equally. One service could be assigned 500m (50ms), the second service could be assigned 100m (10ms), and the final two services could be assigned 200m (20ms) for a total of 1000m (100ms).
Nodes With More Than One CPU
A node with a single CPU is reasonable to think about, but it’s not realistic. What changes if the node has two CPUs?
Figure 2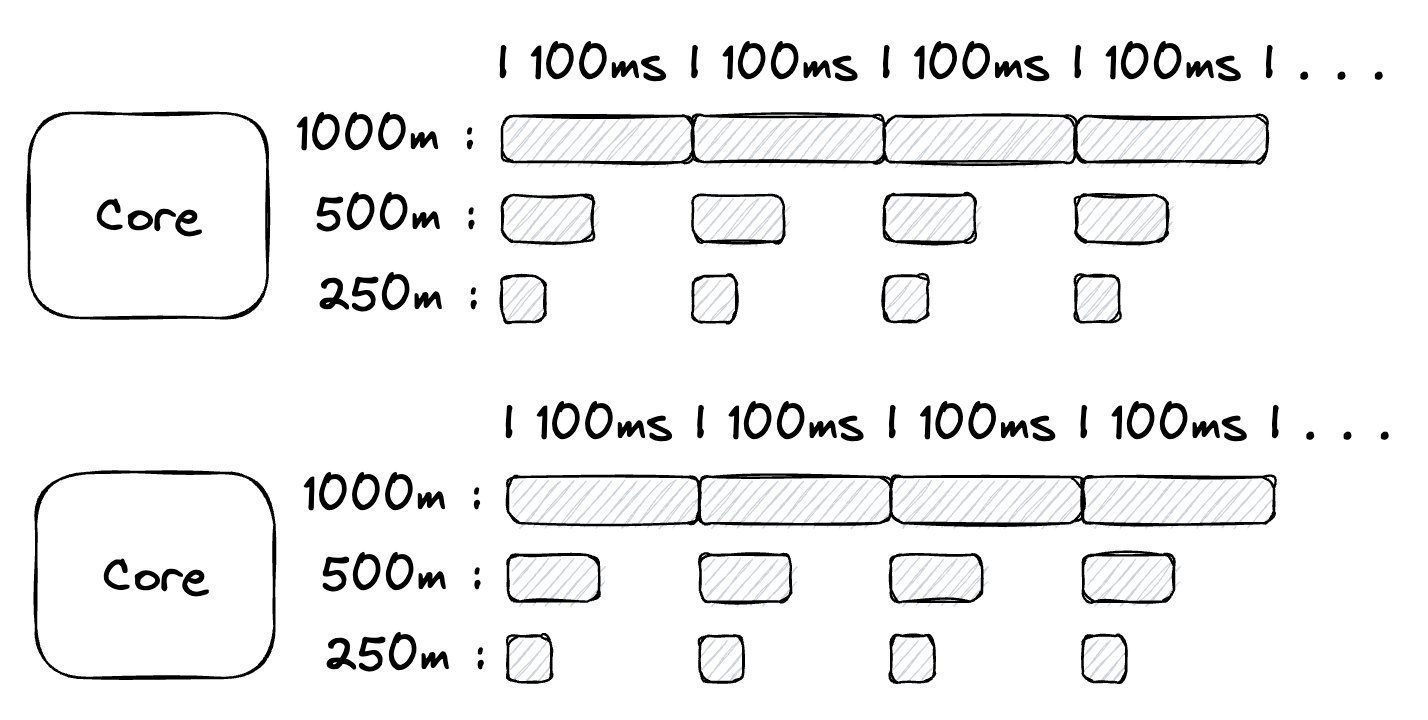
Now there is 2000m (200ms) of time on the node for each cycle that can be assigned to the different services running on the node. If 4 services were running on the node, the CPU time could be assigned like this:
Listing 2
Service1 : Limit 1250m : Time 125ms : Total 1250m (125ms)
Service2 : Limit 250m : Time 25ms : Total 1500m (150ms)
Service3 : Limit 250m : Time 25ms : Total 1750m (175ms)
Service4 : Limit 250m : Time 25ms : Total 2000m (200ms)
In listing 2, I have assigned Service1 1250m (125ms) of time on the node. That means Service1 will get one entire 100ms cycle of time to itself and will share 25ms of time from the second 100ms cycle that is available. The other three services are assigned 250m (25ms), so they will share that time on the second 100ms cycle. When you add all that time up, the full 2000m (200ms) of time on the node is assigned.
Figure 3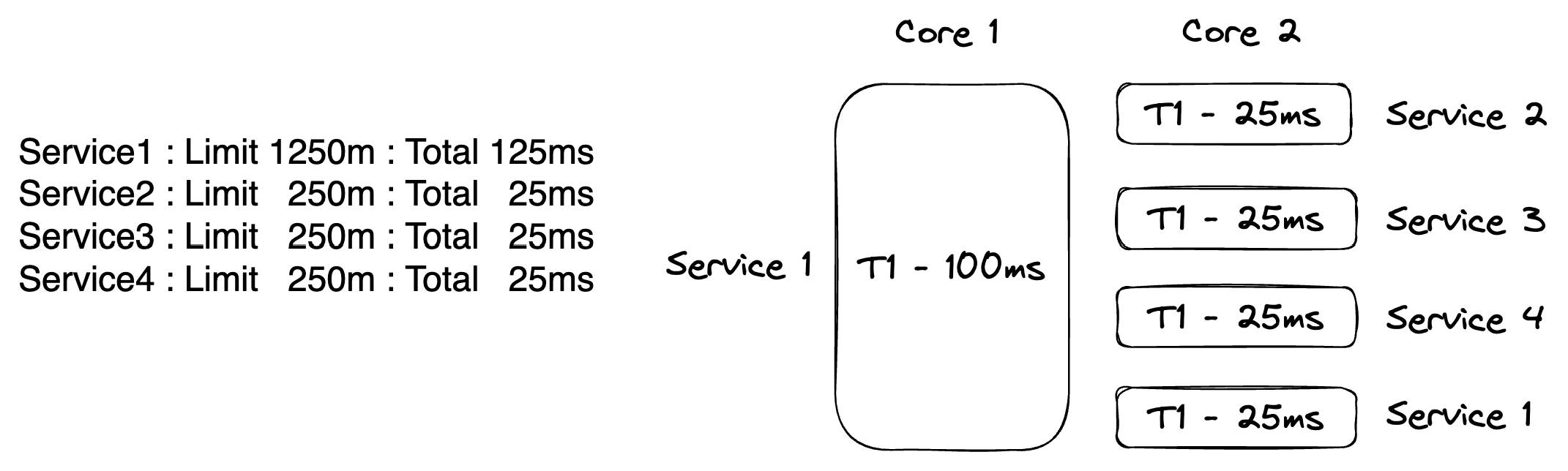
Figure 3 tries to visualize the previously described assignments of time on a node with two CPUs. This drawing assumes each service is running as a single OS threaded program, where each OS thread is assigned to a single CPU and runs for the full time configured for each service. In this configuration, the least number of OS threads are being used to run the four services, minimizing as much context switch overhead as possible.
In reality however, there is no CPU affinity and OS threads are subject to a typical 10ms time slice by the operating system. This means what OS thread is executing on which CPU at any given time is undefined. The key here is that K8s will work with the OS to allow Service1 to always have 125ms of time on the node when it’s needed on every 200ms cycle.
Multi-Threaded Services
In reality things are even more complicated because when services are running with multiple OS threads, all the OS threads will be scheduled to run on the available CPUs and the sum of those running OS threads per service will be regulated to the assigned limit value.
Figure 4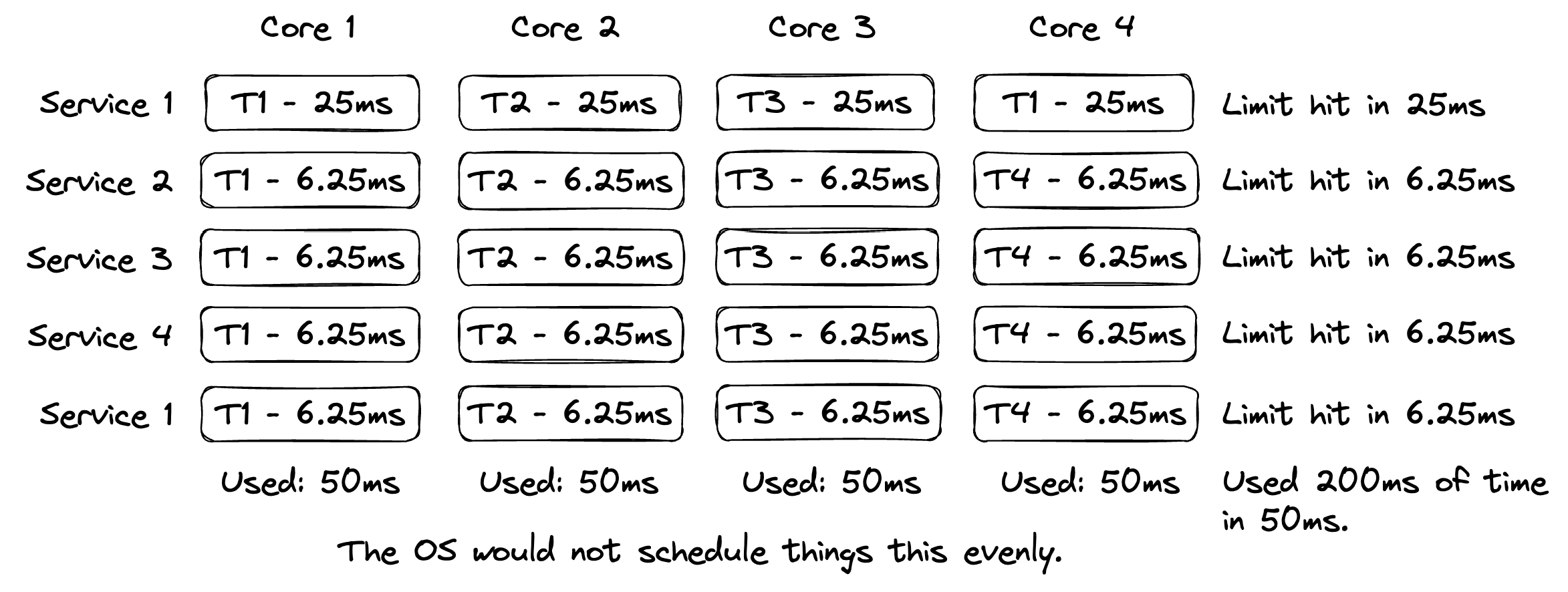
Figure 4 tries to capture a single cycle of services, each running with four OS threads, on a four CPU node, with the same limits as the last example. You can see limits are hit four times quicker, with extra context switching (beyond the 10ms OS thread time slice), resulting in less work getting done over time.
In the end, this is the key to everything.
A limit at or below 1000m (100ms) means the service will only use a single CPU’s worth of time on every cycle.
For services written in Go, this is critically important to understand since Go programs run as CPU bound programs. When you have a CPU bound program you never want more OS threads than you have cores.
Go Programs are CPU Bound
To understand how Go programs run as CPU bound programs, you need to understand the semantics of the Go scheduler.
Figure 5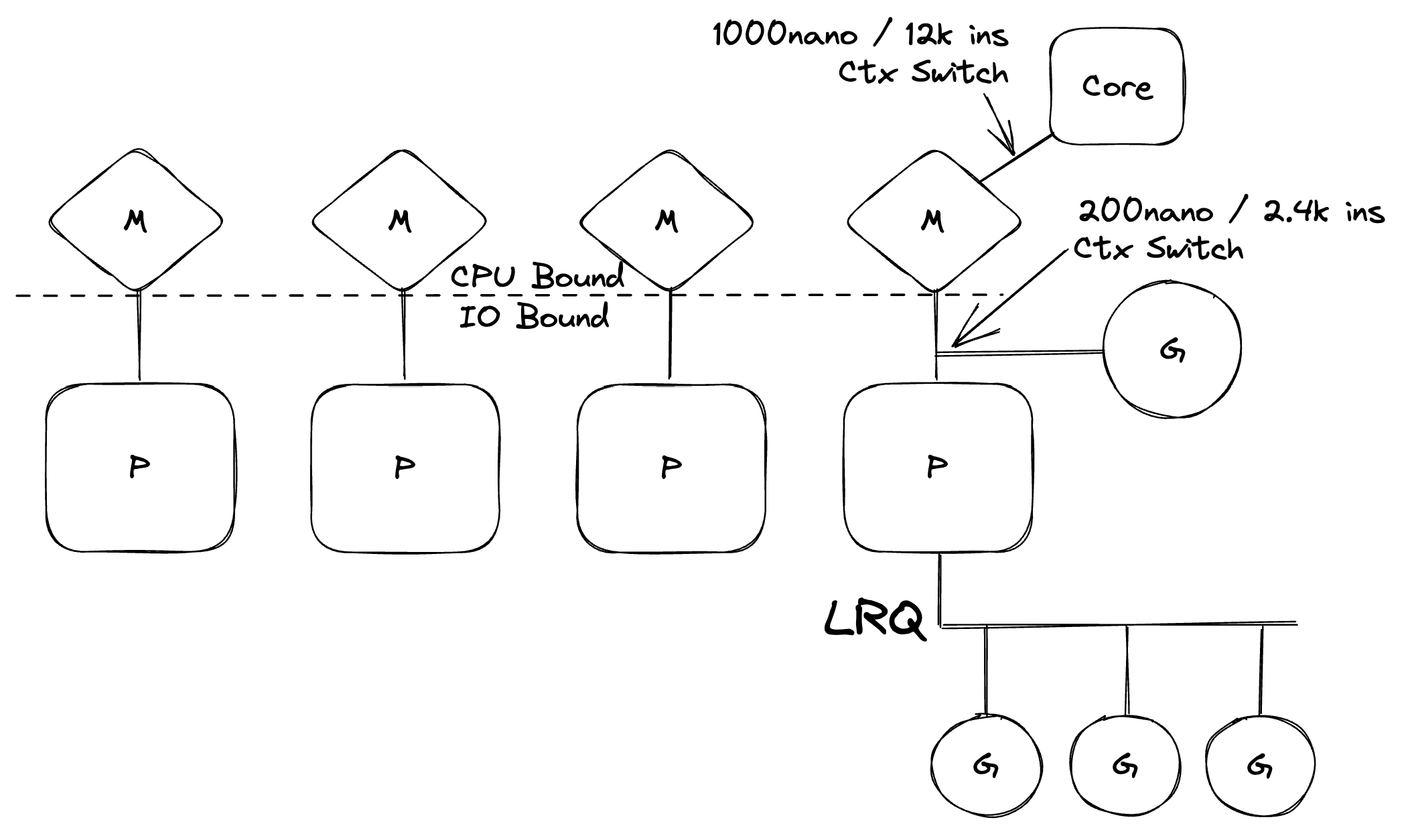
There is a lot going on in Figure 5, but it gives you a high-level semantic view of the scheduler. In the diagram, P is a logical processor, M stands for machine and represents an OS thread, and the G is a Goroutine. I will ask you to read this series I wrote back in 2018 to dive deep into this topic.
https://www.ardanlabs.com/blog/2018/08/scheduling-in-go-part1.html
I hope you take the time to read that series, but if you don’t have time now it’s ok. I am going to jump to the conclusion and you will need to trust me.
What’s important is that the Go scheduler takes IO bound workloads (executed by G’s on M’s) and converts them into CPU bound workloads (executed by M’s on Cores). This means your Go programs are CPU bound and this is why the Go runtime creates as many OS threads as there are cores on the machine it’s running on.
If you read the series, you will understand why you never want more OS threads than you have cores when running CPU bound workloads. Having more OS threads than you have cores will cause extra context switches that will slow down your program from getting application work done.
Proving The Semantics
How can I prove all of this?
Luckily I can use the service repo and run load through a Go service running in a K8s cluster. I will use KIND (K8s in Docker) for the cluster and configure my Docker environment to have four CPUs. This will allow me to run the Go service as a four OS threaded Go program and a single OS threaded Go program while being assigned a limit of 250m (25ms).
If you want to follow along, clone the service repo and follow the instructions in the makefile to install everything you need.
First I will bring up the cluster. From inside the root folder for the cloned repo, I will run the make dev-up command.
Listing 3
$ make dev-up
Creating cluster "ardan-starter-cluster" ...
✓ Ensuring node image (kindest/node:v1.29.1) 🖼
✓ Preparing nodes 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
Set kubectl context to "kind-ardan-starter-cluster"
The make dev-up command starts a K8s cluster using KIND and then loads all the containers needed in the local KIND image repository.
Listing 4
$ make dev-update-apply
Next I will run the make dev-update-apply command to build the Go service images, load them in the local repository, and then apply all the YAML to the cluster to get all the PODs running.
Once the system is up and running, the make dev-status command will show me this.
Figure 6
At this point, the configuration has the sales service running as a single OS threaded Go program with a limit of 250m (25ms).
Listing 5
Limits:
cpu: 250m
Requests:
cpu: 250m
Environment:
GOMAXPROCS: 1 (limits.cpu)
When I run the make dev-describe-sales command, I can see the 250m (25ms) limit is set and the GOMAXPROCS environment variable is set to 1. This will force the sales service to run as a single OS threaded Go program. This is how I want to run when the Go service is set with a limit of 1000m or less.
Now I can put some load through the system. First I need a token.
Listing 6
$ make token
{"token":"eyJhbGciOiJSUzI1NiIsImtpZCI6IjU0YmIyMTY1LTcxZTEtNDFhNi1hZjNlLTdkYTRhM ..."}
Once I have a token, I need to place that in an environment variable.
Listing 7
$ export TOKEN=<Copy Token From Above>
With the TOKEN variable set, I can now run a small load test. I will run 1000 requests through the system using 100 concurrent connections.
Listing 8
$ make load
Summary:
Total: 10.5782 secs
Slowest: 2.7859 secs
Fastest: 0.0070 secs
Average: 0.9515 secs
Requests/sec: 94.5341
Once the load finishes, I see that at my optimal configuration on this cluster, the Go service is handling ~94.5 requests per second.
Now I will comment out the GOMAXPROCS env setting from the deployment YAML.
Listing 9
env:
# - name: GOMAXPROCS
# valueFrom:
# resourceFieldRef:
# resource: limits.cpu
This is the best way I have found to set the GOMAXPROCS variable to match the CPU limit setting for the service. Uber has a module that does this as well, but I have seen it fail at times.
This change will cause the Go service to use as many OS threads (M) as there are cores, which is the default behavior. In my case that will be 4 since I configured my Docker environment to use 4 CPUs. After adding comments to his part of the YAML, I need to re-apply the deployment.
Listing 10
$ make dev-apply
Once the changes have been applied, I can check that the Go service is running with the new settings.
Listing 11
Limits:
cpu: 250m
Requests:
cpu: 250m
Environment:
When I run the make dev-describe-sales command again, I notice the GOMAXPROCS setting is no longer showing. This means the Go service is running with the default number of OS threads.
Now I can run the load again.
Listing 12
$ make load
Summary:
Total: 38.0378 secs
Slowest: 19.8904 secs
Fastest: 0.0011 secs
Average: 3.4813 secs
Requests/sec: 26.2896
This time I see a significant drop in throughput processing requests. I went from ~94.5 requests per second to ~26.3 requests per second. This is dramatic since the load size I am using is small.
Conclusion
The Go runtime doesn’t know it’s running in K8s and by default will create an OS thread for every CPU that is on the node. If you are setting CPU limits for your service, it’s up to you to set the GOMAXPROCS value to match. Listing 10 shows you how to set the GOMAXPROCS directly in your deployment YAML.
I wonder how many Go services running in K8s under limits are not setting the GOMAXPROCS environment variable to match the limit setting. I wonder how much over provisioning those systems are experiencing because the nodes are not running as efficiently as they otherwise could. This stuff is complicated and anyone managing a K8s cluster needs to think about these things.
I have no clue if services running in other programming languages are subject to the same inefficiencies. The fact that Go programs run as CPU bound at the OS/hardware level is a root cause of this inefficiency. So this might not be a problem with other languages.
I have not taken any time to review memory limits, but I’m sure similar issues exist. You might need to look at the use of GOMEMLIMIT to match the K8s memory limits if any are configured. This could be the next post I focus on.



