

Introduction
A blockchain is an integrated solution of different computer science problems in the form of a single, append-only, publicly available, transparent, and cryptographically auditable database that runs in a distributed and decentralized environment.
I’ve heard many times that blockchain is a technology looking for a problem to solve. I disagree with that assessment because the tech and computer science behind blockchain has practical uses in everyday engineering problems. One use of this technology that comes to mind is a dependency management verification system.
What if we wanted a way to guarantee that anytime we pull code from a VCS (Version Control System) it’s the same exact code regardless of when we pull it?
Figure 1
Figure 1 shows a simplified workflow for a system that could provide a way to verify the code we pull is the same as it was in the past. The system consists of a database that can maintain a hash (value) for any repository in a VCS at some tag (key). We could build a client tool that can pull the code from the VCS, hash the code on disk, query the database for the hash value, and compare the two hashes to make sure they are the same. If the key doesn’t exist, then the system could reach out to the VCS directly, append a new record, and return the hash.
This is brilliant because if one byte of the code has changed (since the first time we pulled the code) the hash won’t match and we’ll know someone did something funny with that version of code. That is possible since a developer can delete a tag, update the code, and reapply the tag.
For personal use this system works great since we trust ourselves not to play any funny games with the database. However, what if we wanted others to use the system? We need a way to prove two things:
Existing records in the database are never updated. The only operations performed against the database are READ and APPEND.
Auditable Database
One way to solve this problem is to make sure the database is auditable. In other words, a way for others to validate none of the data has been altered once appended. This can be accomplished with cryptography.
Figure 2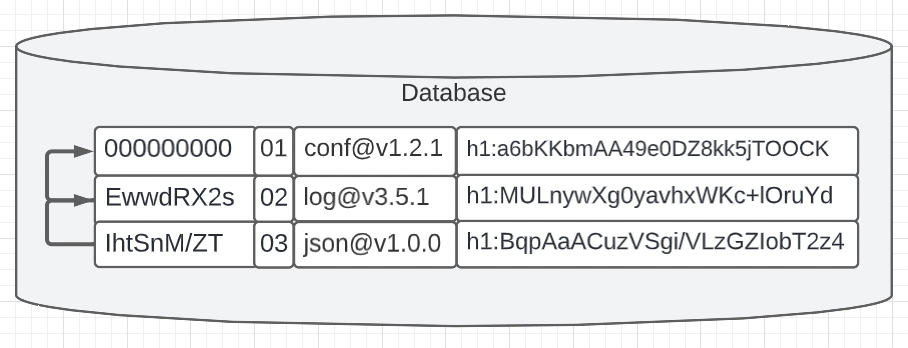
Figure 2 shows a change that would make the database cryptographically auditable. We could add two new fields that represent the hash of the previous record and a record number. The hash is calculated against all the data represented in each record so if any record is altered, the hash would be different. Since the hash of each record is based on the hash of the previous record, the records are essentially chained together. The higher in the chain you want to change a record, the larger number of records below need to change to keep the cryptographic audit trail in place.
With these two new fields, an audit of the database can take place at any time. Starting at any record, hashes are produced and checked all the way down. This will allow users to trust that we have never tampered with the database.
Transparency
We have a solution for the auditing problem, but now we have a transparency problem. The system is being hosted by us which requires others who want to use the system to trust us. Nothing is stopping us from altering the database and fixing all the hashes so the database remains cryptographically sound, who would know?
What we need is to add support in the client tool to allow people to download a copy of the database for themselves and compare their copy of the database with the one in production. It’s important people are comfortable that no shenanigans are going on. The best part is they don’t need the entire database. They can start from any point since the cryptographic audit trail is chained together. They just need a way to update their copy of the database over time to keep us honest.
Centralized Ownership
Now that we have a solution for transparency, what recourse do people have if they notice we have altered the database? What we need is the ability for others to host the database themselves. No one should take the risk of one person or company owning and controlling the database. This solves another problem of us being a single point of failure, everyone being completely dependent on us, and everything coming out of our own pocket.
One idea is asking someone else to host a second database and putting the databases behind a load balancer like Caddy or an API gateway like KrakenD.
Unfortunately, if we do this the databases won’t stay in sync.
Figure 3
Figure 3 shows what could happen between each database. Since the load balancer is balancing the queries between the two databases, different keys and some of the same keys will exist as different record numbers.
This is never a problem when the hash information for a given key is the same in both databases. However, there is a chance that the hash for the same key can be different in each database. Look at ops@v1.7.5 and see how a different hash value exists. The code for that dependency was changed between the time the original database was queried compared to when the other database was queried.
Which one is right? Technically they both are but that doesn’t help users. The need is to have redundancy where anyone could talk to either database and get the same result.
Liveness and Replication
Having multiple versions of the database breaks the consistency we are looking for. The value of any key must always be the same regardless of the database a user accesses. This is tricky because we want all databases to have the ability to READ and APPEND records.
We could designate just one database for appending new records and have all the other databases for reading. If a read database has a missing key, it can send the request to the append database where it can perform the work. The new record could then be replicated to other databases.
Figure 4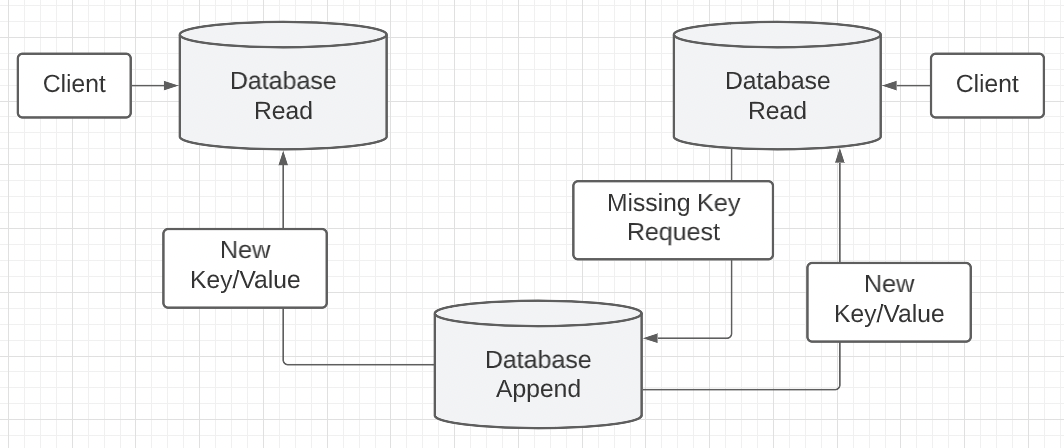
However, if the append database goes down the system loses its liveness since this solution creates centralization around the append database and a single point of failure. One solution could be to elect a new append database, but there is a lot of complexity in this solution. One problem is having no guarantee all the read databases are in sync at the time an election would need to take place.
It would be best to maintain a decentralized solution where each database can perform both reads and appends. This would allow the system to maintain liveness even if a database goes down. To implement a system like this we will need a peer-to-peer (P2P) network where we can implement P2P replication.
Figure 5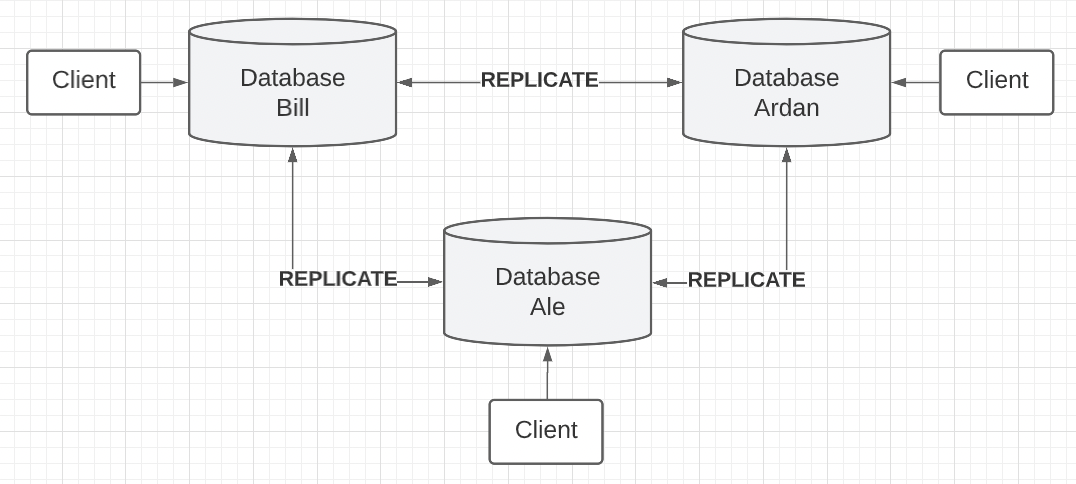
Figure 5 shows the new architecture where different people and entities can maintain, use, and share their own database with the public. This solution provides liveness and decentralization while maintaining a single replicated database.
Atomic Appends
A new question presents itself, how can we guarantee each database is exactly the same when different appends are taking place on local databases? Each append increments the record number and is tied to the cryptographic audit trail for that database. We need some way to implement an atomic write across all the databases in this decentralized P2P network.
We could implement a simplified form of a consensus protocol that will coordinate which database gets to perform the next append to the database and sync that append across the P2P network before the next append. There are two popular consensus protocols that we could use to model our system, Proof of Work (PoW) and Proof of Authority (PoA).
What are the advantages and disadvantages of each consensus protocol we are considering?
Figure 6: Proof Of Work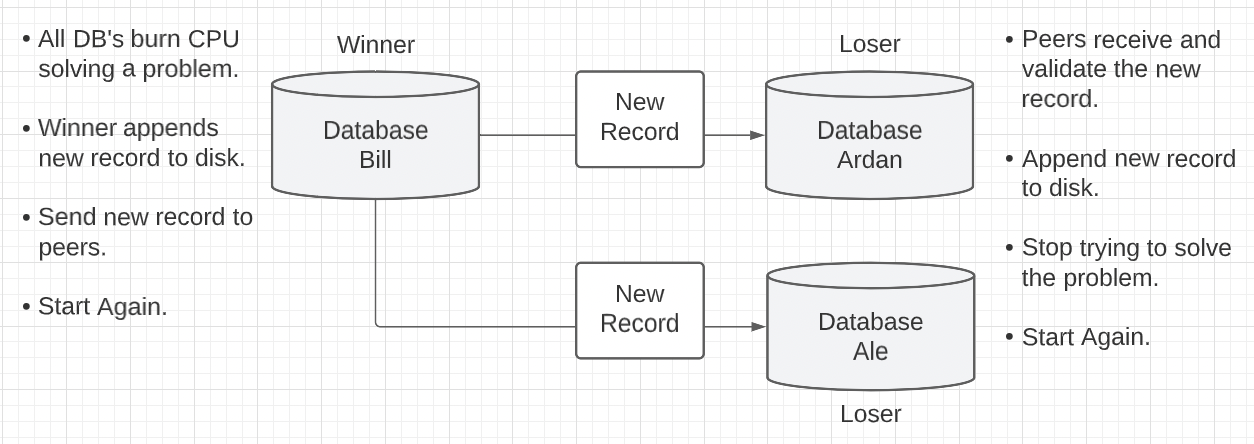
Cons
- Databases must compete against each other for the next append to the database.
- Each database is using energy to compete without knowing who will win or when.
- There is no consistent cadence between each new append to the database.
Pros
- The system stays 100% decentralized.
\
Figure 7: Proof Of Authority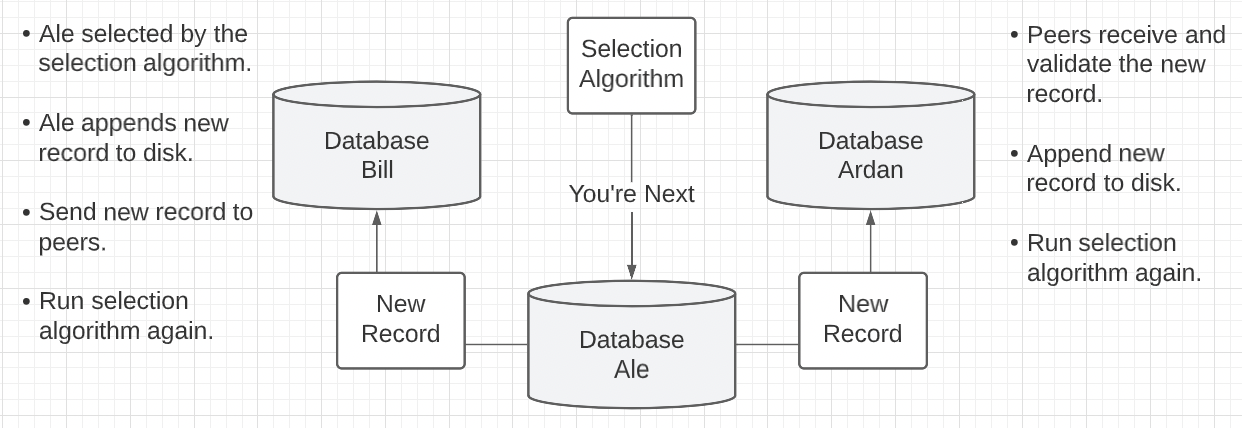
Cons
Need a centralized registration system where nodes are authorized to append.
Need this list of authorized nodes to be known by all other authorized nodes.
Need a selection algorithm that each authorized node runs at the same time.
- Which is deterministic so nodes get the same answer on each timed run.
- Which is random to evenly distribute selections.
Pros
- There is a consistent cadence between each new append to the database.
- Energy wastefulness of PoW is removed.
\
Choosing which consensus protocol to use comes down to a few things.
- Do we want pure decentralization or are we willing to live with some centralization?
- The PoW model is fairly simple, but are we ok with the energy inefficiency?
- The PoA model is energy efficient, but are we ok with the added complexity?
Note: With even more complexity we could remove the centralized registration system in our PoA solution and build a second P2P network of nodes that can handle registration, coordination, and the management of selection.
I’m all about reducing complexity until you absolutely need it. That being said, being wasteful has real consequences on any system both internally and externally. These different engineering tradeoffs are difficult since there is no obvious right answer.
Pending Records
There is another problem which exists regardless of the consensus protocol we choose. Consensus takes some time to complete once it starts. While consensus is taking place, a new record generated by a client will need to be kept as a pending record and the client will need to be told it can’t have an answer until this pending record is officially appended to the database. Which makes the speed at which consensus is reached very important.
What’s more, clients talking to different databases could generate many pending records while consensus is taking place. These pending records need to be placed in a holding area until the next round of consensus starts. We could add a memory pool to the architecture to store these pending records.
Figure 8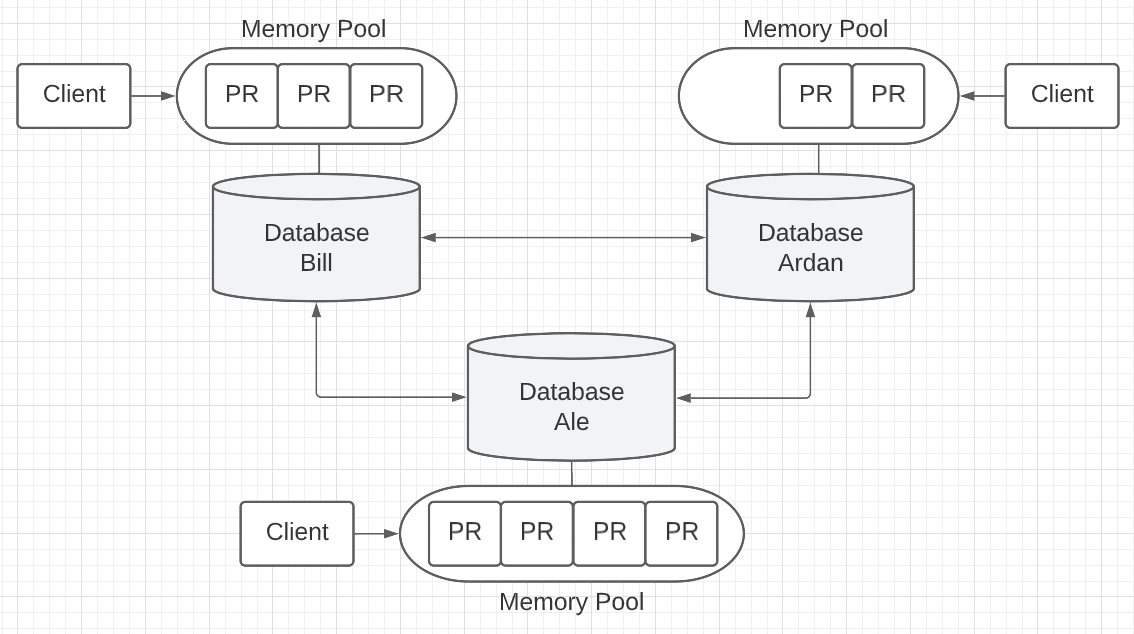
There is more. These pending records in the memory pool need to be shared across the P2P network so there is consistency and reliability in the system. If we choose PoW and these pending records are not shared, the pending records in the mempool of a particular database may never be appended since that database could possibly never win a competition. If we choose PoA, then the user needs to wait until that database is selected by the selection algorithm.
Figure 9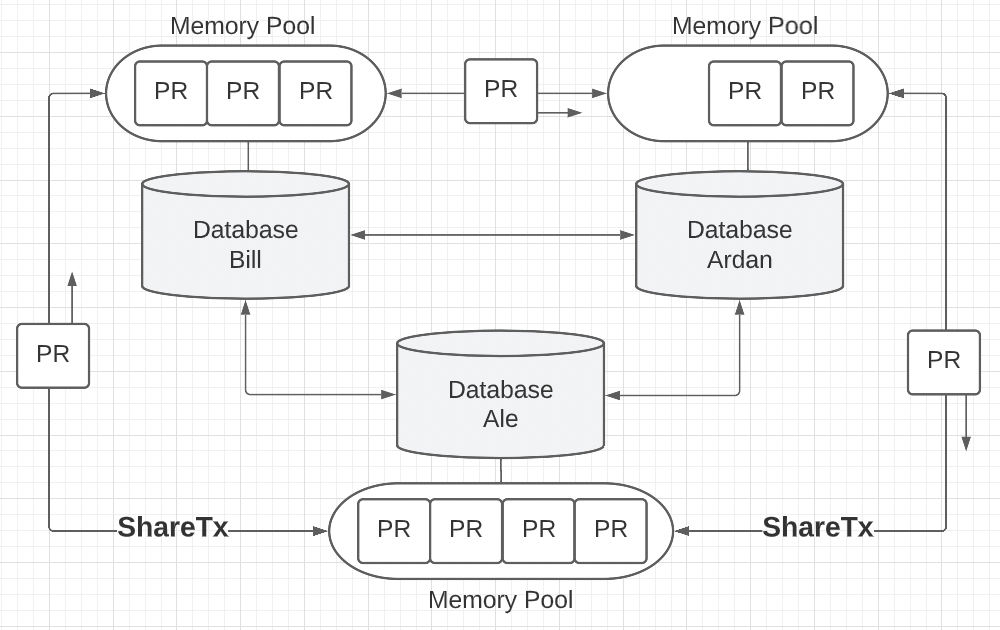
Thanks to the memory pool we can now be more efficient appending and sharing new records. Instead of sending one record at a time over the P2P network, we can now send a batch of records based on what is currently stored in the mempool.
Now with solutions in place for a decentralized P2P network, pending records being shared, a consensus protocol providing atomic writes, transparency, and the database containing a cryptographic audit trail, we can build and deploy the system. Much of the engineering and strategy we are going to apply is also used by blockchain technologies.
Incentive
We found solutions for the technical problems, however there is a non-technical problem we need to solve. How do we create an incentive for others to host and expose their own database publicly? Running a database requires money, time, and commitment. We can’t expect people to do this out of the kindness of their own heart. This is the 800 pound gorilla in the room and we have to be very careful how we proceed.
Maybe the incentive of having secure and durable source code is enough. Hosting a database may cost near to nothing (if we use PoA). If we decide we want pure decentralization and use PoW, then it may not be insignificant to host a database. We will burn CPU cycles on a regular basis.
If we choose PoA, how do we prevent people from adding a database and being a bad actor? It doesn’t cost them anything except time and a little money. This could be fun entertainment for them. Maybe we need to consider changing PoA to Proof Of Stake (PoS) and require people or companies to stake some money before they can participate?
The moment money is involved, things begin to go to hell in a handbasket. There is so much more to talk about when it comes to incentive and protecting the network from bad actors. We will need to leave this conversation for the next post.
Conclusion
In this post, we discussed how the different technical aspects of blockchain technology could be used to build a single, append-only, publicly available, transparent, and cryptographically auditable database that runs in a distributed and decentralized environment for managing version of source code. We walked through the different issues and engineering tradeoffs along the way.
At the end, we began to talk about incentives and how we need to be very careful with the incentive option we choose. In the next post, we will explore the incentive options in more detail and show how currency and financial investing can take root.



