

Introduction
In the first three posts, I explained there were four aspects of a blockchain that this series would explore with a backing implementation provided by the Ardan blockchain project.
- Digital accounts with electronic signatures and verification
- Transaction distribution and synchronization between computers
- Redundant storage and consensus by different computers
- Detection of any fraud to past transactions
The first post focused on how the Ardan blockchain provides support for digital accounts, signatures, and verification. The second post focused on transaction distribution and synchronization between different computers. The third post, focused on how the Ardan blockchain handles consensus between different computers which results in the redundant storage of the blockchain database. In this fourth post, I will focus on how the Ardan blockchain can detect forgery or changes to the underlying blocks and transaction data.
Source Code
The source code for the Ardan blockchain project can be found at the link below.
https://github.com/ardanlabs/blockchain
It’s important to understand this code is still a work-in-progress and that things are being refactored as more is learned.
Cryptographic Audit Trail
A blockchain is a database that provides a cryptographic audit trail of its data. Anyone with a full copy of the database can recompute the audit trail and verify the data they have is correct. It’s this audit trail that provides the ability to detect fraud.
In the Ardan blockchain, there are three fields in the block header that provide the cryptographic audit trail. These fields provide the ability to guarantee any node’s copy of the blockchain database is a proper copy without fraud.
Figure 1: Blocks and Transactions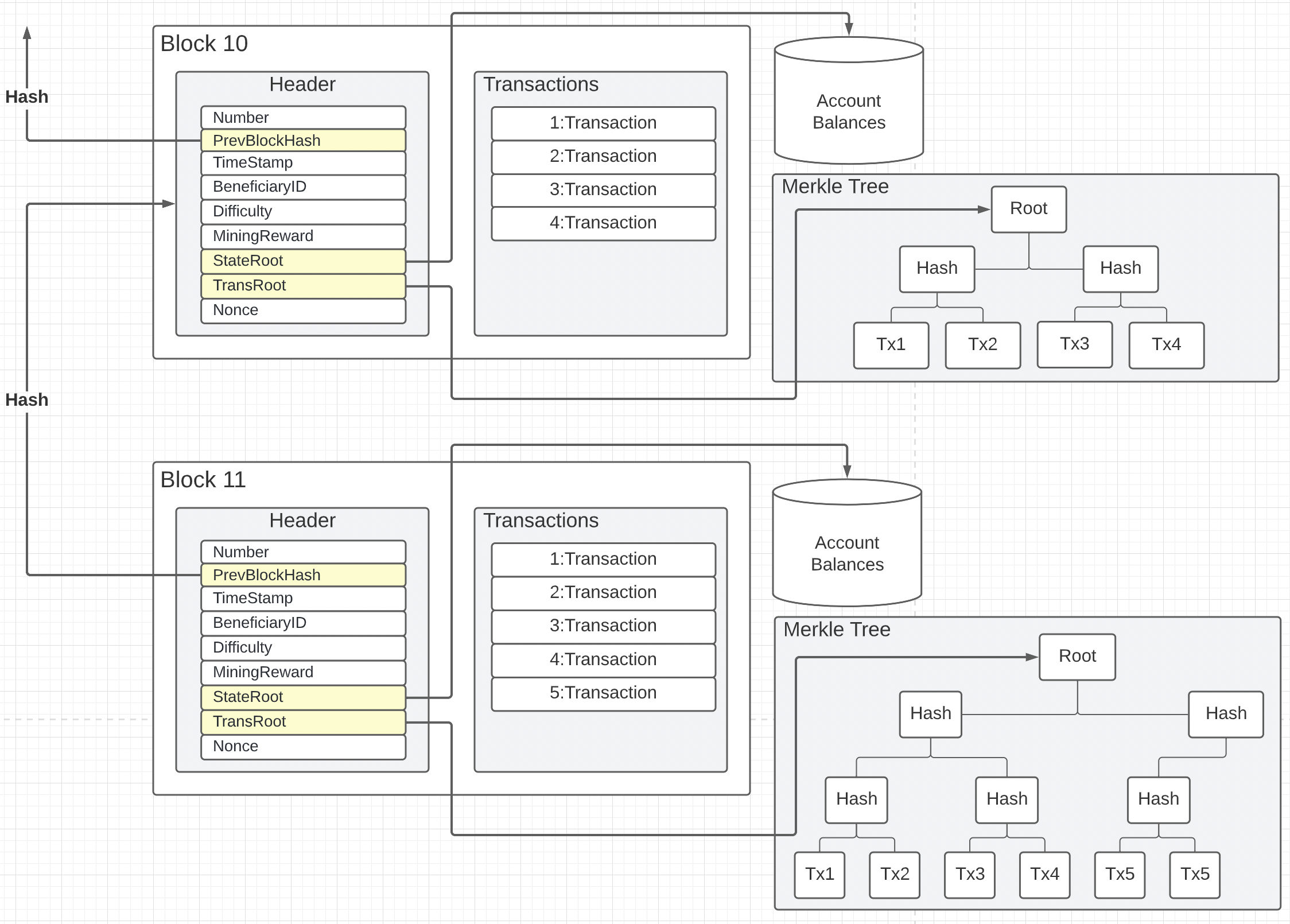
Figure 1 shows two blocks from the Ardan blockchain. Each block contains a header and the set of ordered transactions that belong to the block. Notice in the block header there is a PrevBlockHash, StateRoot, and a TransRoot field colored in yellow with lines going in different directions. These fields make up the cryptographic audit trail for the Ardan blockchain. With these three fields, the entire blockchain database can be verified and checked for fraud.
Previous Block Hash
Every block is chained together by a block number and a hash of the previous block header. When a node receives a new block (say block 11), it must verify that the value of the PrevBlockHash field matches the hash of the previous block header (block 10) currently stored in the local blockchain. If the hashes don’t match, then the node sending the block is currently maintaining a different fork.
Figure 2: Previous Hash Audit Trail
Figure 2 shows the previous hash cryptographic audit trail. Imagine a network of 100 nodes competing in mining blocks and suddenly two nodes mine block 10 at roughly the same time. Each node would accept their own block 10 over the other which leads to a fork between these two nodes. Depending on network topology and latency, it’s hard to tell which block 10 the other 98 nodes will get first and accept into their local chain.
Now imagine a random node successfully mine’s block 11 and eventually the block is received by node 1 and 2. When node 1 receives block 11 there is no problem. Block 11 is the next expected block and the previous block hash matches. Node 1 accepts the block into their local chain assuming other validations pass.
When node 2 receives block 11 there is a problem. The block number is correct, but the previous block hash does not match the hash for the block 10 currently saved in the local blockchain. In this case the block is rejected, however node 2 is not ready to admit that their block 10 has not been accepted by the majority of nodes, at least not yet.
Figure 3: Accepting A Fork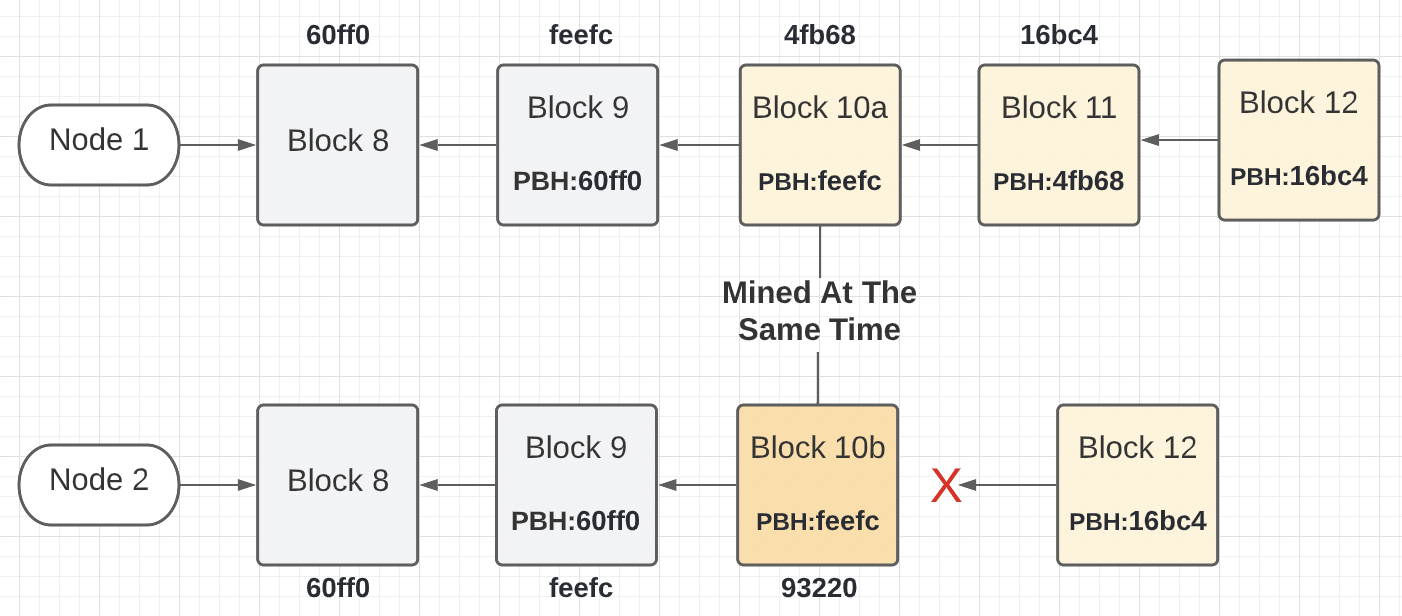
Figure 3 shows what happens when node 1 and 2 received block 12 from a random node on the network. As before, node 1 accepts block 12 into its local chain and node 2 rejects the block. The rejection this time is because node 2 is still waiting for block 11 and this is block 12.
In the Ardan blockchain, when a node is behind by two block numbers, it accepts that their local chain has forked away from the true chain and begins what is called a reorganization. This reorganization will require node 2 to remove block 10b and request blocks 10 through the latest block from known peers on the network.
Thanks to each block holding a block number and the hash of the previous block, the blockchain database can provide a guarantee that each copy is an accurate copy and each node over time is maintaining the proper blocks in their local chain. Anyone with all the blocks can recalculate the block header hashes from the origin block to the latest and validate the chain.
Transaction Root
The TransRoot field represents a hash of the transactions belonging to a block using a Merkle tree. This field allows the blockchain to provide a guarantee that the set of transactions associated with the block do belong to this block. It can also provide a way to validate an individual transaction belongs to a block as well.
Figure 4: Merkle Tree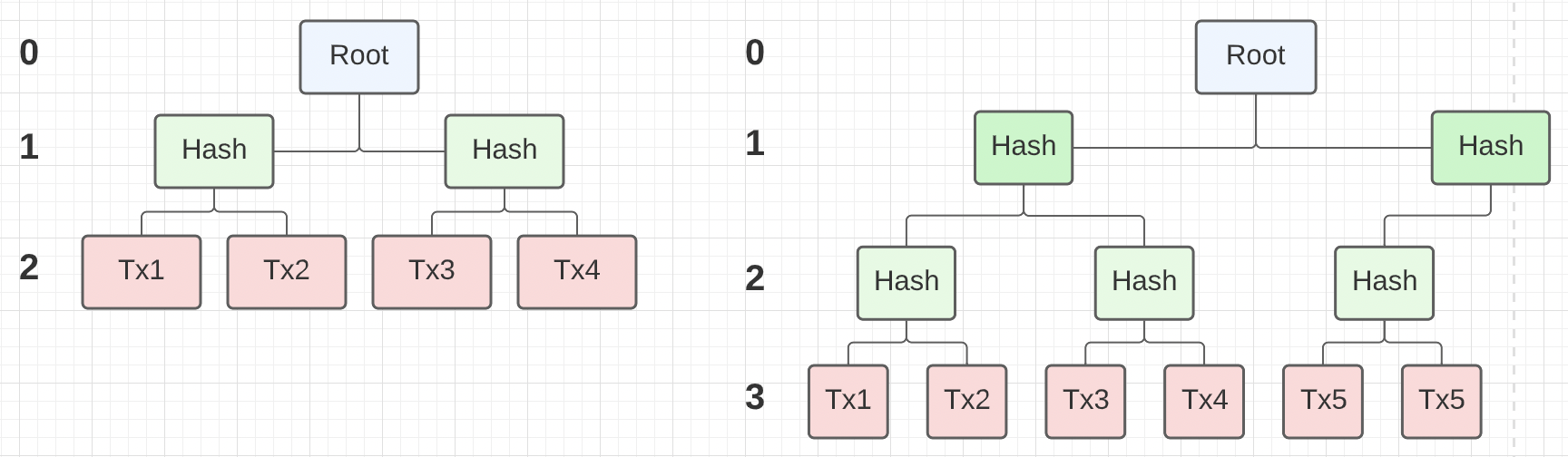
Figure 4 shows two Merkle trees for the transactions that exist in the two blocks shown in figure 1. The transactions are not stored as a Merkle tree in storage, but as an ordered list. In the Ardan blockchain when a block is read from storage, a Merkle tree is created and maintained while that block remains in memory.
Note: When you have an odd number of transactions, the last transaction is duplicated in the tree to make a proper pair. This is why you see transaction 5 twice.
The Merkle tree provides a single hash for all the transactions in the tree. The order the transactions are loaded in the tree matter. The highest level of the tree contains each transaction itself which is individually hashed to start. As you move up each layer in the tree, new hashes are generated by merging each pair of connected nodes and hashing again until you eventually have a hash for the entire tree, which is called the root hash.
As an example for the tree with four transactions, Tx1 and Tx2 are individually hashed and then those two hashes are joined (left side+right side) into a single value and hashed again producing a parent node. Same happens with Tx3 and Tx4 to produce their parent node. Finally those two parent nodes are joined together (left side+right side) into a single value and hashed to produce the final root hash.
When a new block is received by a node, even if the previous block hash is correct, the Merkle tree is reproduced and the value of the Merkle tree root is compared with the block header’s TransRoot value. If those values don’t match, there is fraud. Granted, the possibility of two blocks having a different TransRoot value but the same value for the block header hash is slim to none, but technically it’s possible. Having this TransRoot value in the block header strengthens the cryptographic audit trail at the block level.
What’s really brilliant about a Merkle tree is you don’t need the entire tree to prove any given transaction does or doesn’t belong to a block. All you need is a small piece of the tree.
Let’s say you wanted to prove that transaction number 3 did exist in both trees.
Figure 5: Merkle Tree Proof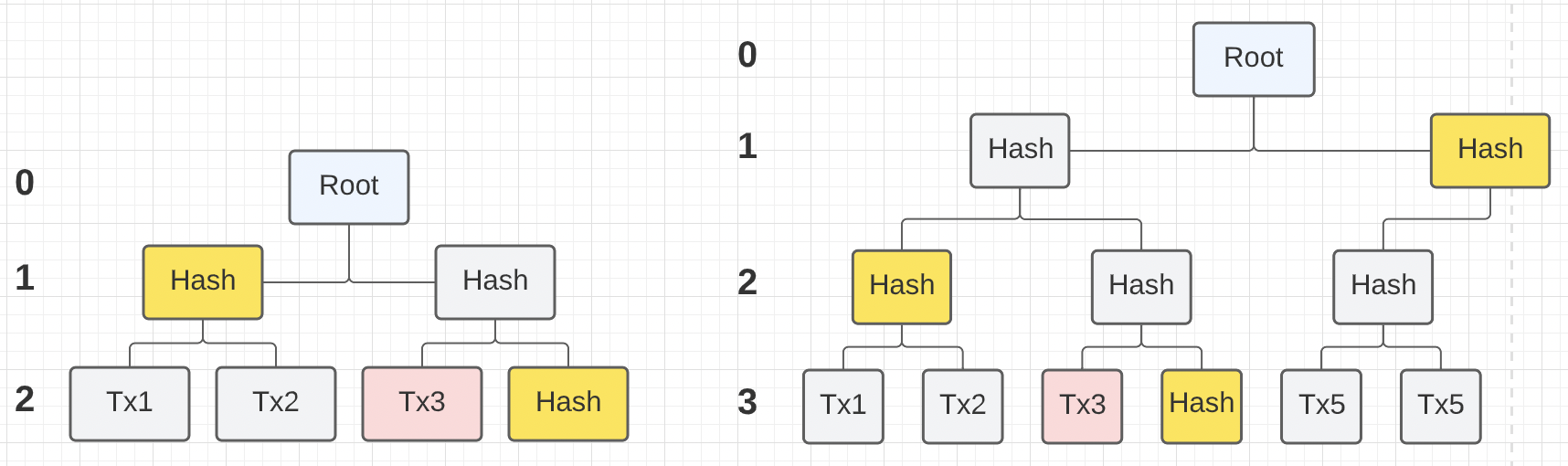
Figure 5 shows in yellow what parts of the tree you would need to prove transaction 3 existed in each tree. Given the ability to produce the hash for transaction 3 on your own, you could ask the node for a Merkle proof for transaction 3 in a specified block. If the transaction did exist in that block, the node could return you back the hash values in yellow and a value of 0 or 1 to indicate which order to merge the hash values before hashing, left side or right side.
For the tree on the left, the proof for transaction 3 could come back in an array like this:
0 1
—------------------------------------------
| Hash: Value-Lvl-2 | Hash: Value-Lvl-1 |
| Order: 1 | Order: 0 |
—------------------------------------------
In the proof array for index 0, the proof is saying to take the hash of Tx3 and merge it with this hash value from level 2. Since the order is 1, this hash value in the proof comes second in the merge.
// Since the value is 1, join the hash of Tx3 and index 0 in this order.
hashTx3Tx4 = sha256.Sum256( Hash(Tx3) + Proof[0].Hash )
Taking the result of the last hash operation, merge that with the next hash in the proof array. Since the order value is 0, the hash in the proof comes first in the merge.
// Since the value is 0, join the hash of index 1 and the current hash.
root = sha256.Sum256( Proof[1].Hash + hashTx3Tx4 )
Now if the root hash value that is calculated matches the hash value in the TransRoot field, there is a guarantee that transaction 3 belongs to that block.
State Root
The StateRoot represents a hash of the in-memory account balance database. This field allows the blockchain to provide a guarantee that the accounting of the transactions and fees for each account on each node is exactly the same.
In the Ardan blockchain, the account database is a map of account information by account address.
Listing 1: Account Database
01 type AccountID string
02
03 type Account struct {
04 AccountID AccountID
05 Nonce uint64
06 Balance uint64
07 }
08
09 type Database struct {
10 mu sync.RWMutex
11 genesis genesis.Genesis
12 latestBlock Block
13 accounts map[AccountID]Account
14 storage Storage
15 }
Listing 1 shows how the accounts database on line 13 is declared. The account database is never written to storage and it doesn’t need to be. Once a new block is received and validated, the transactions and fees are applied to the different accounts. At the start of creating a new block to be mined, a hash of this map is created and stored in the block under the StateRoot field. This allows each node to validate the current state of the peer’s accounts database as part of block validation.
Listing 2: Hashing The Account Database
01 func (db *Database) HashState() string {
02 accounts := make([]Account, 0, len(db.accounts))
03 db.mu.RLock()
04 {
05 for _, account := range db.accounts {
06 accounts = append(accounts, account)
07 }
08 }
09 db.mu.RUnlock()
10
11 sort.Sort(byAccount(accounts))
12 return signature.Hash(accounts)
13 }
Listing 2 shows how the accounts database is hashed. It’s critically important that the order of the account balances are exact when hashing the data. The Go spec does not define the order of map iteration and leaves it up to the compiler. Since Go 1.0, the compiler has chosen to have map iteration be random. This function sorts the accounts and their balances into a slice first and then performs a hash of that slice.
When a new block is received, the node can take a hash of their current accounts database and match that to the StateRoot field in the block header. If these hash values don’t match, then there is fraud going on by the peer and their block would be rejected.
Conclusion
What makes a database a blockchain database is the cryptographic audit trail. A blockchain database is a replicated database and by being such, must have safeguards to make sure everyone’s copy is the same and that anyone can verify that. This is what sets a blockchain apart from other types of databases. You can see how the Ardan blockchain has taken ideas from Bitcoin and Ethereum to provide a cryptographic audit trail.



