

Introduction
In the first two posts, I explained there were four aspects of a blockchain that this series would explore with a backing implementation provided by the Ardan blockchain project.
- Digital accounts with electronic signatures and verification
- Transaction distribution and synchronization between computers
- Redundant storage and consensus by different computers
- Detection of any fraud to past transactions
The first post focused on how the Ardan blockchain provides support for digital accounts, signatures, and verification. The second post focused on transaction distribution and synchronization between different computers. In this third post, I will focus on how the Ardan blockchain handles consensus between different computers which results in the redundant storage of the blockchain database.
Source Code
The source code for the Ardan blockchain project can be found at the link below.
https://github.com/ardanlabs/blockchain
It’s important to understand this code is still a work-in-progress and that things are being refactored as more is learned.
Consensus
Consensus in computer science is the process of getting different computers in a distributed and decentralized environment to all agree about something. With a blockchain, that something is a proposed block of transactions to be included in the blockchain database for every node running on a computer.
There are two consensus protocols widely used today by blockchains. One is proof of work (POW) and the other is proof of stake (POS). Bitcoin and Ethereum currently use POW for their consensus protocol. However, Ethereum will be switching to POS at some point in 2022. Think about POW as consensus by competition where POS is consensus by committee.
Note: There are other consensus protocols that are also used by blockchains such as proof of space and proof of elapsed time to name a few.
When implementing a consensus protocol you also need to choose between safety or liveness. If a blockchain were to choose safety, then nodes would need to wait for all other nodes in the network to vote and agree about a proposed block before another block can be proposed. If liveness is chosen, then nodes don’t need to wait to keep proposing blocks. One benefit of liveness is that it allows a blockchain to maintain high availability, since nodes can keep proposing blocks without waiting.
Bitcoin and Ethereum both use liveness. When a node is successful in mining a block, the node will write the block immediately into their blockchain database and then propose the block for inclusion by other nodes. This is why at times (more often than not) there are forks, different versions of the blockchain database on different nodes. When a fork occurs, the consensus protocol will eventually determine which fork is correct and those nodes with the wrong fork will reset. In the end, there really isn’t any true consensus until roughly 10 blocks have been mined and those blocks can be found in all of the nodes actively participating in the network.
It’s important that Blockchain systems choose liveness over safety since individual mining nodes are not reliable. At any time a country like China could shut down thousands of nodes, which would bring an entire network to a halt if you needed to wait for nodes that no longer exist.
The Ardan blockchain uses a POW and liveness consensus protocol just like Bitcoin and Ethereum. The implementation for the Ardan blockchain is driven by two different mining workflows depending if the node is successful in mining the block or not.
Validation
The other big part of a blockchain consensus protocol is how a block is validated. Over time these rules can change as a blockchain goes through upgrades. It’s always interesting when nodes are in the process of upgrading since blocks can be invalidated by nodes running older or newer versions of the software. There are always forks that occur and eventually get resolved once all the nodes on the network are running the same version.
Here are the current validation checks (with a code example) that are being performed by the Ardan blockchain for all newly proposed blocks.
Listing 1: Block Difficulty
01 if proposedBlock.Header.Difficulty < latestBlock.Header.Difficulty {
02 return fmt.Errorf("message")
02 }
Listing 1 shows the block difficulty check. If the proposed block’s difficulty is not the same or greater than the parent block’s difficulty, it can’t be accepted. Failing this check could identify a node trying to propose a block without performing the proper amount of work.
Listing 2: Block Hash
01 hash := proposedBlock.Hash()
02 if !isHashSolved(proposedBlock.Header.Difficulty, hash) {
03 return fmt.Errorf("message")
04 }
01 func isHashSolved(difficulty int, hash string) bool {
02 const match = "00000000000000000"
03 if len(hash) != 64 {
04 return false
05 }
06 return hash[:difficulty] == match[:difficulty]
07 }
Listing 2 shows the block hash check. A proposed block has to prove the proper amount of work has been performed by finding a nonce that produces a proper hash based on the rule set by the protocol. In the Ardan blockchain, that is a hash with a number of leading zeros that match the difficulty number. Here the proposed block is hashed once and then checked for the proper number of zeros. Failing this check could identify a node running under a different version of code that has changed the hash requirement or just deciding to try and sneak a block with less difficulty into the chain.
Listing 3: Block Number
01 if proposedBlock.Header.Number != latestBlock.Header.Number + 1 {
02 return fmt.Errorf("message")
03 }
Listing 3 shows the block number check. A proposed block must be the next block in the sequence of blocks based on the node’s latest block. If the latest block is block number 4, the proposed block must be set as block number 5. Failing this check could identify a node that is running a forked chain or is not properly in sync.
Listing 4: Block Validation - Chain Forked
01 nextNumber := latestBlock.Header.Number + 1
02 if proposedBlock.Header.Number >= (nextNumber + 2) {
03 return ErrChainForked
04 }
Listing 4 shows the chain forked check. This check identifies if the local node’s blockchain database is not valid. The idea is that if the next proposed block is two or more block numbers ahead of this node’s latest block, this node’s blockchain database has forked from the current chain that has been widely accepted by other nodes. At this point, the node needs to remove their current latest block and begin to resync the local blockchain database from the previous block on.
Listing 5: Block Parent Hash
01 if proposedBlock.Header.ParentHash != latestBlock.Hash() {
02 return fmt.Errorf("message")
03 }
Listing 5 shows the parent hash check. A proposed block has a parent hash value and that hash should match the hash of the current latest block. Failing this check could identify a node that is running a forked chain since it has a different parent block.
Listing 6: Block Timestamp
01 parentTime := time.Unix(int64(latestBlock.Header.TimeStamp), 0)
02 blockTime := time.Unix(int64(proposedBlock.Header.TimeStamp), 0)
03 if !blockTime.After(parentTime) {
04 return fmt.Errorf("message")
05 }
Listing 6 shows the block timestamp check. A proposed block must have a timestamp that is greater than the latest block. Failing this check could identify a node that has a problem with its clock or is trying to play games on the network.
Listing 7: Block Time Difference
01 parentTime := time.Unix(int64(latestBlock.Header.TimeStamp), 0)
02 blockTime := time.Unix(int64(proposedBlock.Header.TimeStamp), 0)
03 dur := blockTime.Sub(parentTime)
04 if dur.Seconds() > time.Duration(15*time.Second).Seconds() {
05 return fmt.Errorf("message")
06 }
Listing 7 shows the block time difference check. A proposed block can’t be older than 15 minutes from its parent block. Failing this check could identify a node that has a problem with its clock or is trying to play games on the network. This is a check that is commented out for the Ardan blockchain since development and running the network is sporadic.
Mining Code
Now that you have seen the code used to perform block validation, next is to show you the code that handles the mining workflows. The mining workflows implement the POW and liveness parts of the consensus protocol.
Figure 1: Mined Block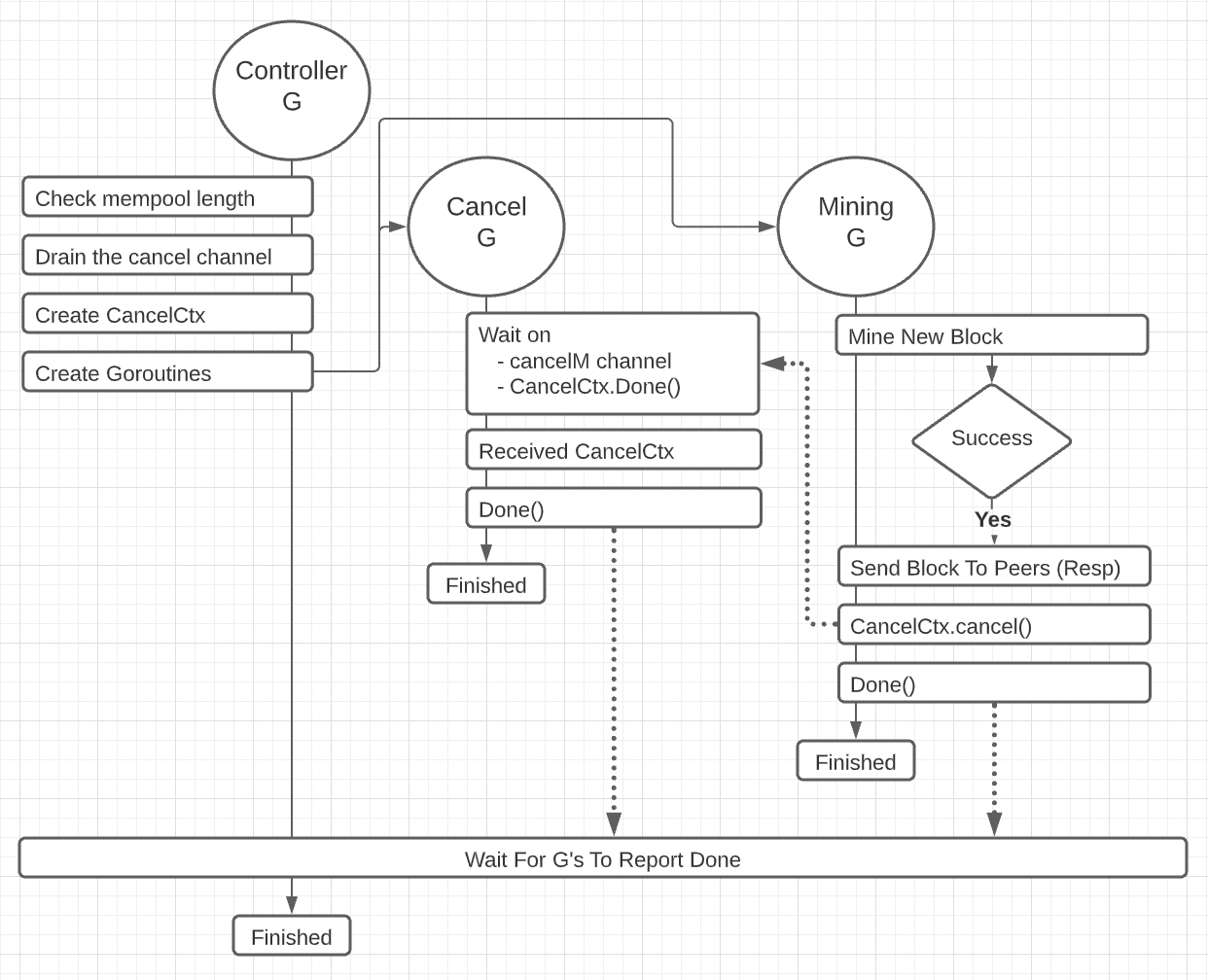
Figure 1 shows a workflow diagram of what happens when a node is successful in mining a block before any other node.
You can see how three goroutines (G) are involved in the process of mining. The controller goroutine manages the workflow for the entire mining process. The mining goroutine performs the actual work of mining and the cancel goroutine is responsible for canceling mining when signaled to do so. However, in this scenario the mining goroutine signals the cancel goroutine to indicate that mining is complete.
Now take a look at the workflow for when a node is not successful in mining a new block before any other node.
Figure 2: Received Proposed Block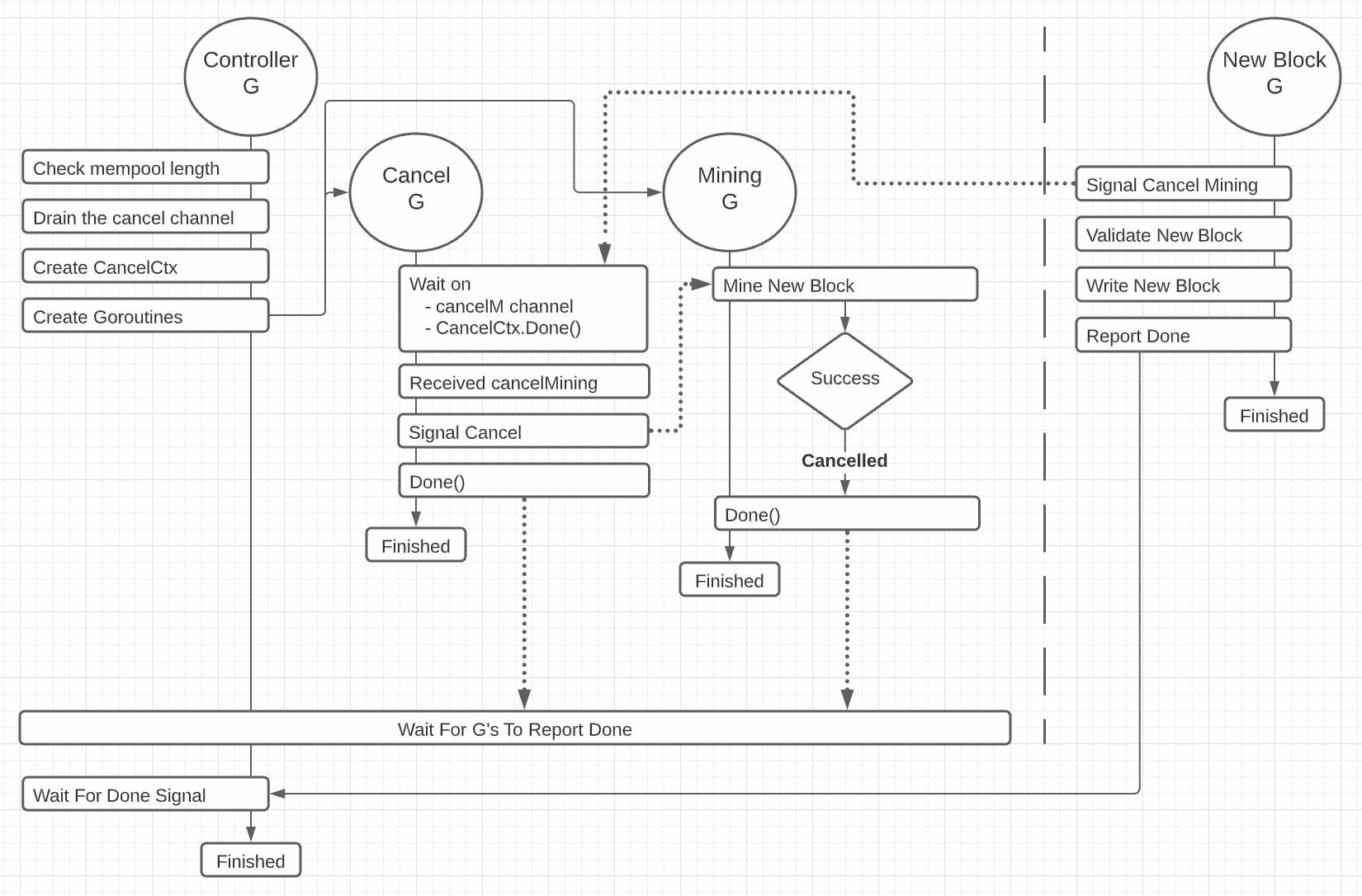
Figure 2 shows a workflow diagram of what happens when a node receives a proposed block on a fourth goroutine handling the request while in the process of mining a new block. This requires that the mining operation is canceled and the proposed block is verified and written to disk. The cancellation of the mining operation and the synchronization between all the goroutines involved is what’s tricky in this workflow.
To start, I will walk through the code that sets up the controller, cancel, and mining goroutines.
Worker and State Packages
In the blockchain layer of the Ardan blockchain project, there is a package named worker with a source code file named worker.go. This is where the code for the different workflows described above have been implemented.
Listing 8: Getting Things Started
01 package worker
02
03 type Worker struct {
04 state *state.State
05 wg sync.WaitGroup
06 ticker time.Ticker
07 shut chan struct{}
08 startMining chan bool
09 cancelMining chan chan struct{}
10 txSharing chan storage.BlockTx
11 evHandler state.EventHandler
12 baseURL string
13 }
14
15 func Run(state *State, evHandler EventHandler) {
16 w := &worker{
17 state: state,
18 ticker: *time.NewTicker(peerUpdateInterval),
19 shut: make(chan struct{}),
20 startMining: make(chan bool, 1),
21 cancelMining: make(chan chan struct{}, 1),
22 txSharing: make(chan storage.BlockTx, maxTxShareRequests),
23 evHandler: evHandler,
24 baseURL: "http://%s/v1/node",
25 }
. . .
Listing 8 shows the Worker type and Run function. The Run function starts the goroutines that implement the different workflows to keep the node in sync and healthy. Since this post is focusing on mining, look at the startMining and cancelMining channels on lines 08-09. These channels are connected to the mining workflow. Notice how they are constructed as buffered channels of 1 on lines 20-21.
Note: When you see a channel constructed with a bool, this is an indication that there will be signaling with data, but the data is arbitrary. When you see a channel constructed with the empty struct (struct{}), this is an indication that only a close operation will be conducted.
The State value that is passed into the Run function needs access to the Worker value so State APIs can sync, shutdown, and signal the start and cancellation of workflows. The Worker value needs access to the State value since that provides the core business logic. So there is a problem. Go doesn’t allow the criss-crossing of imports between packages. To solve this problem, the worker package has an import to the state package, and the state package declares an interface called Worker.
Listing 9: Worker Interface
01 package state
02
03 type Worker interface {
04 Shutdown()
05 Sync()
06 SignalStartMining()
07 SignalCancelMining() (done func())
08 SignalShareTx(blockTx storage.BlockTx)
09 }
10
11 type State struct {
. . .
27 Worker Worker
28 }
Listing 9 shows the declaration of the Worker interface from the state package. This interface allows for the decoupling of a worker implementation. These five methods are required to allow the state package to execute or signal the different events managed by the worker package. On line 27, you see how the Worker field is declared using the Worker interface.
Listing 10: Worker to State to Worker Assignments
03 import (
04 "github.com/ardanlabs/blockchain/foundation/blockchain/state"
05 )
. . .
15 func Run(state *State, evHandler EventHandler) {
16 w := &worker{
17 state: state,
18 ticker: *time.NewTicker(peerUpdateInterval),
19 shut: make(chan struct{}),
20 startMining: make(chan bool, 1),
21 cancelMining: make(chan chan struct{}, 1),
22 txSharing: make(chan storage.BlockTx, maxTxShareRequests),
23 evHandler: evHandler,
24 baseURL: "http://%s/v1/node",
25 }
26
27 state.Worker = &w
. . .
Listing 10 shows how the worker package imports the state package on line 04, which means the state package can no longer import worker. Thanks to the Worker interface declared by the state package, the assignment of the worker value to state.Worker on line 27 can take place.
The other nice thing about this interface is it allows you to replace the project’s worker package with your own implementation for learning purposes.
Listing 11: Node Sync
15 func Run(state *State, evHandler EventHandler) {
. . .
29 w.sync()
. . .
In listing 11, the call to sync on line 29 of the Run function makes sure the blockchain database and state for the node is in sync with the rest of the network before participating in any blockchain activities.
Listing 12: Starting Goroutines
15 func Run(state *State, evHandler EventHandler) {
. . .
31 operations := []func(){
32 w.peerOperations,
33 w.miningOperations,
34 w.shareTxOperations,
35 }
36
37 g := len(operations)
38 w.wg.Add(g)
39
40 hasStarted := make(chan bool)
41
42 for _, op := range operations {
43 go func(op func()) {
44 defer w.wg.Done()
45 hasStarted <- true
46 op()
47 }(op)
48 }
49
50 for i := 0; i < g; i++ {
51 <-hasStarted
52 }
53 }
Listing 12 shows the rest of the Run function. Once the blockchain node is in sync with the network, a set of operation functions are executed as different goroutines. These operation functions manage the different workflows that are needed to keep the blockchain node healthy and in sync with the rest of the network.
There are three operation functions that exist today: peerOperations: Manages the finding of new nodes on the network. miningOperations: Manages the mining of new blocks. shareTxOperations: Manages the sharing of new transactions across the network.
In listing 12 on lines 31-35, an array of operation functions is constructed and initialized with the three functions defined above. Then the worker’s WaitGroup field is updated on line 38 to reflect the three goroutines that are going to be created for each operation. On line 40, a channel is constructed so the Run function can’t return until it’s known that all three of the goroutines that are about to be created are up and running.
Line 42-48 creates the three goroutines using a literal function. The literal function sets up the call to Done on return, signals that the goroutine is running, and then calls the operation function which blocks until shutdown.
Finally on lines 50-52, the Run function waits to receive the signals that all the goroutines are up and running. At this point, the node is ready and can participate in blockchain activities.
Listing 13: Operational Function: Controller G: Mining Operation
01 func (w *worker) miningOperations() {
02 for {
03 select {
04 case <-w.startMining:
05 if !w.isShutdown() {
06 w.runMiningOperation()
07 }
08 case <-w.shut:
09 w.evHandler("worker: miningOperations: received shut signal")
10 return
11 }
12 }
13 }
Listing 13 shows the top level code for the operation function that runs mining. The code is an endless for loop that is blocked on two signals. The first signal is used to start a mining operation which it does by calling the runMiningOperation method. The other signal is used to force the function to return which will shutdown the goroutine.
Listing 14: Signal Mining
01 func (w *worker) SignalStartMining() {
02 select {
03 case w.startMining <- true:
04 default:
05 }
06 }
Listing 14 shows the SignalStartMining method which implements one of the behaviors defined by the state.Worker interface. This function is called anytime a state package API wants to start a mining operation. If this buffered channel of 1 already has a pending signal, the default case will drop any new signal so the caller doesn’t block. Only one pending signal is required to start a new mining operation.
Listing 15: runMiningOperation
01 func (w *worker) runMiningOperation() {
02 length := w.state.QueryMempoolLength()
03 if length == 0 {
04 return
05 }
06
07 defer func() {
08 length := w.state.QueryMempoolLength()
09 if length > 0 {
10 w.signalStartMining()
11 }
12 }()
. . .
Listing 15 shows the beginning code for the runMiningOperation method that is called in listing 13 when a mining signal is received. The logic in this method is at the core of what the controller goroutine does in the workflow diagrams shown at the beginning of this post.
On line 02, a check is made to verify there are transactions in the mempool. Then on lines 07-12, a defer function is declared to be called once the mining operation is complete. This allows the method to signal a new mining operation to start again once this function returns if there are new transactions in the mempool.
Listing 16: runMiningOperation continued
01 func (w *worker) runMiningOperation() {
. . .
14 var wait chan struct{}
15 defer func() {
16 if wait != nil {
17 <-wait
18 }
19 }()
. . .
Listing 16 shows the next section of code in runMiningOperation which is a critical piece of the logic. This code blocks the method from completely returning until the wait channel is closed. Notice how the channel is being declared with the empty struct on line 14. If this channel remains set to its zero value construction during mining, the defer function doesn’t need to wait before returning.
This logic is required for when the node is not successful in mining the block first and it has to wait on a request goroutine to process a new proposed block. I will explain more about that scenario later.
Listing 17: runMiningOperation continued
01 func (w *worker) runMiningOperation() {
. . .
21 select {
22 case <-w.cancelMining:
23 default:
24 }
25
26 ctx, cancel := context.WithCancel(context.Background())
27 defer cancel()
28
29 var wg sync.WaitGroup
30 wg.Add(2)
31
32 go func() {
// Cancel Goroutine
42 }()
43
44 go func() {
// Mining Goroutine
66 }()
67
68 wg.Wait()
69 }
Listing 17 shows the rest of the control logic for starting and managing the mining operation. Lines 21-24 are used to drain the cancel mining channel so it’s empty before the mining starts. You don’t want the mining to end before it actually begins. I don’t expect there to be a pending signal, but just in case I think it’s best to clear the channel.
Lines 26-27 constructs a context for the purpose of canceling the mining operation if a new proposed block is received by another node. The cancel function will provide this facility.
Lines 29-30 constructs a WaitGroup to track the cancel and mining goroutines that are created next. Following the creation of those two goroutines is the call to Wait on line 68. This call forces the runMiningOperation method to wait for the cancel and mining goroutines to complete before returning. Once the runMiningOperation method returns, the two defer functions shown in listings 8 and 9 will execute.
Listing 18: Cancel Goroutine
01 func (w *worker) runMiningOperation() {
. . .
32 go func() {
33 defer func() {
34 cancel()
35 wg.Done()
36 }()
37
38 select {
39 case wait = <-w.cancelMining:
40 case <-ctx.Done():
41 }
42 }()
. . .
Listing 18 shows the goroutine for canceling the mining operation. On lines 38-41, the goroutine blocks waiting for one of two different signals to be received. If the cancel mining signal is received on line 39, then a new proposed block has been received and the mining operation needs to be canceled. Notice how the wait channel declared on line 14 in listing 16 is assigned when receiving this signal.
If the context canceled signal is received on line 40, then this node was successful in mining the new block. The mining goroutine will call that context value’s cancel function when it successfully mines a block to signal this event.
Once any signal is received, this goroutine can terminate and the literal defer function on lines 33-36 will be executed. The cancel function is called first, but in this scenario the context was already canceled and since the cancel function can be called multiple times, no extra logic is needed. Then the WaitGroup value is decremented by 1 with the call to Done.
Listing 19: Mining Goroutine
01 func (w *worker) runMiningOperation() {
. . .
44 go func() {
45 defer func() {
46 cancel()
47 wg.Done()
48 }()
49
50 block, duration, err := w.state.MineNewBlock(ctx)
51 if err != nil {
52 switch {
53 case errors.Is(err, ErrNotEnoughTransactions):
54 // Log: Not enough transactions in mempool
55 case ctx.Err() != nil:
56 // Log: Mining Canceled
57 default:
58 // Log: Something failed
59 }
60 return
61 }
62
63 if err := w.proposeBlockToPeers(block); err != nil {
64 // logging
65 }
66 }()
. . .
Listing 19 shows the goroutine for performing the mining operation. On line 50, the goroutine calls the MineNewBlock method of the state value to perform the mining. Notice how the context created on line 26 in listing 17 is passed into that method. That gives the cancel goroutine the ability to send a signal to this goroutine to stop mining by calling that context value’s cancel function.
In the case where the MineNewBlock method returns an error, then a new proposed block was received and the runMiningOperation method can return. If the MineNewBlock method is successful, then a new block is mined by this node and leads to executing the code on line 63, which proposes this new block to the other known blockchain nodes.
In either case, once the mining goroutine is complete, its defer function on lines 45-48 will execute. This will have the cancel goroutine shutdown if it’s still running and decrement the WaitGroup by 1.
New Proposed Block Received
In the workflow diagram for when a new proposed block is received from a different blockchain node, there is a goroutine called the New Block G. This goroutine is a request handler implemented to receive this new proposed block and perform the work of canceling mining, validating, and writing the new block to disk.
Listing 20: New Proposed Block Request Goroutine
01 func (h Handlers) ProposeBlock(
ctx context.Context, w http.ResponseWriter, r *http.Request) error {
02
03 var blockFS storage.BlockFS
04 if err := web.Decode(r, &blockFS); err != nil {
05 return fmt.Errorf("unable to decode payload: %w", err)
06 }
07
08 block, err := storage.ToBlock(blockFS)
09 if err != nil {
10 return fmt.Errorf("unable to decode block: %w", err)
11 }
12
13 if err := h.State.ValidateProposedBlock(block); err != nil {
14 if errors.Is(err, state.ErrChainForked) {
15 h.State.Truncate()
16 return web.NewShutdownError(err.Error())
17 }
18
19 return v1.NewRequestError(err, http.StatusNotAcceptable)
20 }
21
22 resp := struct {
23 Status string `json:"status"`
24 }{
25 Status: "accepted",
26 }
27
28 return web.Respond(ctx, w, resp, http.StatusOK)
29 }
Listing 20 shows the handler function for the new proposed block goroutine defined in figure 2. On lines 03-11, the new proposed block received by a different node is decoded and then on line 13, the ValidateProposedBlock method off the state value is called to perform the work of handling this new proposed block.
Listing 21: Validate Proposed Block
01 func (s *State) ValidateProposedBlock(block storage.Block) error {
02 done := s.Worker.SignalCancelMining()
03 defer done()
. . .
Listing 21 shows the first piece of logic for the ValidateProposedBlock method. The very first thing the method does is cancel the mining operation on line 02 by calling the worker’s SignalCancelMining method. This method returns a function that needs to be called after the ValidateProposedBlock method is finished with all its work. This is setup with a defer on line 03. If the done function is not called, it will block the goroutine running the runMiningOperation method forever.
Listing 22: Signal Cancel Mining
01 func (w *worker) SignalCancelMining() (done func()) {
02 wait := make(chan struct{})
03
04 select {
05 case w.cancelMining <- wait:
06 default:
07 }
08
09 return func() { close(wait) }
10 }
Listing 22 shows the implementation of the SignalCancelMining method from the worker package that was called in listing 21. Here is where the wait channel is constructed, which was talked about in listings 9 and 11.
On lines 04-07, the wait channel is signaled to the cancel goroutine to initiate the canceling of the mining operation in progress. Then on line 09, a literal function is declared and returned that closes this channel, which when called will signal back to the goroutine executing the runMiningOperation method that it can complete its return, as seen in listing 16.
Listing 23: Validate Proposed Block
01 func (s *State) ValidateProposedBlock(block storage.Block) error {
02 done := s.Worker.SignalCancelMining()
03 defer done()
04
05 return s.validateUpdateDatabase(block)
06 }
Listing 23 continues with the logic for the ValidateProposedBlock method. After the signal to cancel mining is complete, the next step is to validate the new proposed block and if the block passed validation, write the block to disk and update the state of the node. This is done with the call to validateUpdateDatabase on line 05.
The logic for validating the block was presented in the beginning of this post.
Conclusion
This third post focused on how the Ardan blockchain handles redundant storage of a single ledger and consensus between different computers. This represents the third of the four aspects of a blockchain that this series will explore with a backing implementation provided by the Ardan blockchain.
In the next post, I will share how the Ardan blockchain provides detection of any forgery to past transactions or the blockchain database.



