

Series Index
Reducing Image Size
Details Specific To Different Languages
Going Farther To Reduce Image Size
Introduction
In the first part, we introduced multi-stage builds, static and dynamic linking, and briefly mentioned Alpine. In this second part, we are going to dive into some details specific to Go. Then we will talk more about Alpine, because it’s worth it; and finally we will see how things play out with other languages like Java, Node, Python, Ruby, and Rust.
So, what about Go?
You might have heard that Go does something very smart: when building a binary, it includes all the necessary dependencies in that binary, to facilitate its deployment.
You might think, “wait, that’s a static binary!” and you’d be right. Almost. (If you’re wondering what a static binary is, you can check the first part of this series.)
Some Go packages rely on system libraries. For instance, DNS resolution, because it can be configured in various ways (think /etc/hosts, /etc/resolv.conf, and some other files). As soon as our code imports one of these packages, Go needs to generate a binary that will call system libraries. For that, it enables a mechanism called cgo (which generally speaking, allows Go to call C code) and it produces a dynamic executable, referencing the system libraries that it needs to call.
This means that a Go program that uses e.g. the net package will generate a dynamic binary, with the same constraints as a C program. That Go program will require us to copy the needed libraries, or to use an image like busybox:glibc.
We can, however, entirely disable cgo. In that case, instead of using system libraries, Go will use its own built-in reimplementations of these libraries. For instance, instead of using the system’s DNS resolver, it will use its own resolver. The resulting binary will be static. To disable cgo, all we have to do is set the environment variable CGO_ENABLED=0.
For instance:
FROM golang
COPY whatsmyip.go .
ENV CGO_ENABLED=0
RUN go build whatsmyip.go
FROM scratch
COPY --from=0 /go/whatsmyip .
CMD ["./whatsmyip"]
Since cgo is disabled, Go doesn’t link with any system library. Since it doesn’t link with any system library, it can generate a static binary. Since it generates a static binary, that binary can work in the scratch image. 🎉
Tags and netgo
It’s also possible to select which implementation to use on a per-package basis. This is done by using Go “tags”. Tags are instructions for the Go build process to indicate which files should be built or ignored. By enabling the tag “netgo”, we tell Go to use the native net package instead of the one relying on system libraries:
go build -tags netgo whatsmyip.go
If there are no other packages using system libraries, the result will be a static binary. However, if we use another package that causes cgo to be enabled, we’re back to square one.
(That’s why the CGO_ENABLED=0 environment variable is an easier way to guarantee that we get a static executable.)
Tags are also used to select which code to build on different architectures or different operating systems. If we have some code that needs to be different on Linux and Windows, or on Intel and ARM CPUs, we use tags as well to indicate to the compiler “only use this when building on Linux.”
Alpine
We briefly mentioned Alpine in the first part, and we said “we’ll talk about it later.” Now is the time!
Alpine is a Linux distribution that, until a few years ago, most people would have called “exotic”. It’s designed to be small and secure, and uses its own package manager, apk.
Unlike e.g. CentOS or Ubuntu, it’s not backed by an army of maintainers paid by a huge company like Red Hat or Canonical. It has fewer packages than these distributions. (With out of the box default repositories, Alpine has about 10,000 packages; Debian, Fedora, and Ubuntu have each more than 50,000.)
Before the rise of containers, Alpine wasn’t very popular, perhaps because very few people actually care about the installed size of their Linux system. After all, the size of programs, libraries, and other system files is usually negligible compared to the size of the documents and data that we manipulate (like pictures and movies for end users; or databases on servers).
Alpine was brought to the spotlight when people realized that it would make an excellent distribution for containers. We said it was small; how small exactly? Well, when containers became popular, everyone noticed that container images were big. They take up disk space; pulling them is slow. (There is a good chance that you’re reading this because you’re concerned by this very problem, right?) The first base images were using “cloud images” which were very popular on cloud servers, and weighed anywhere between a few hundred MB to a few GB. That size is fine for cloud instances (where the image gets transferred from an image storage system to a virtual machine, generally through a very fast local network), but pulling that over cable or DSL internet is much slower. And so distro maintainers started to work on smaller images specifically for containers. But while popular distributions like Debian, Ubuntu, Fedora, struggled to get under 100 MB sometimes by removing potentially useful tools like ifconfig or netstat, Alpine set the score by having a 5 MB image, without sacrificing these tools.
Another advantage of Alpine Linux (in my opinion) is that its package manager is ridiculously fast. The speed of a package manager is usually not a major concern, because on a normal system, we only need to install things once; we’re not installing them over and over all the time. With containers, however, we are building images regularly, and we often spin up a container using a base image, and install a few packages to test something, or because we need an extra tool that wasn’t in the image.
Just for fun, I decided to get some popular base images, and check how long it took to install tcpdump in them. Look at the results:
Base image Size Time to install tcpdump
---------------------------------------------------------
alpine:3.11 5.6 MB 1-2s
archlinux:20200106 409 MB 7-9s
centos:8 237 MB 5-6s
debian:10 114 MB 5-7s
fedora:31 194 MB 35-60s
ubuntu:18.04 64 MB 6-8s
The size is reported with the docker images command and the time was measured by running the following command a few times on a t3.medium instance in eu-north-1
time docker run <image> <packagemanager> install tcpdump
When I’m in Europe, I use servers in Stockholm because Sweden electricity is cleaner than anywhere else and I care about the planet. Don’t believe the bullshit about eu-central-1 being “green”, the datacenters in Frankfurt run primarily on coal.
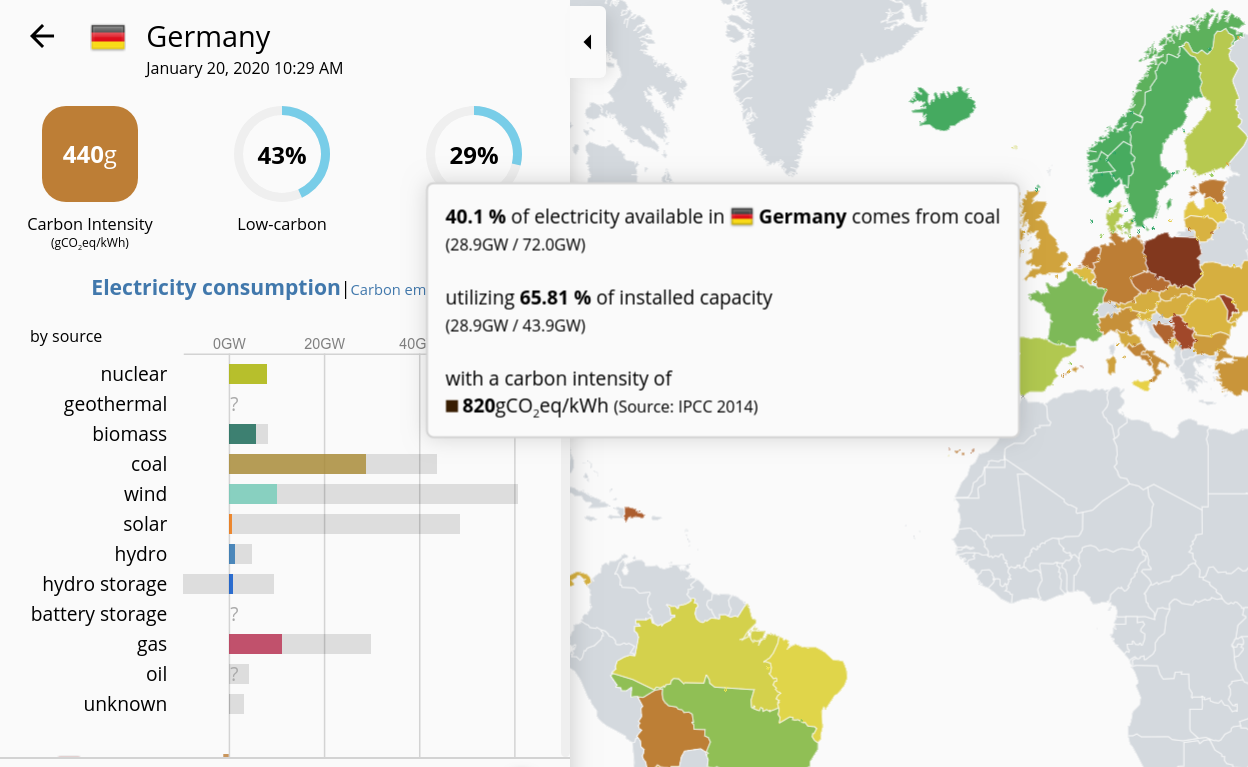
The screenshot is from electricitymap.org and it’s showing that at this very moment, 40% of electricity in Germany comes from coal-fired power plants
If you want to know more about Alpine Linux internals, I recommend this talk by Natanel Copa.
Alright, so Alpine is small. How can we use it for our own applications? There are at least two strategies that are worth considering:
- using
alpineas our “run” stage, - using
alpineas both our “build” and “run” stages.
Let’s try them out.
Using Alpine as our “run” stage
Let’s build the following Dockerfile, and run the resulting image:
FROM gcc AS mybuildstage
COPY hello.c .
RUN gcc -o hello hello.c
FROM alpine
COPY --from=mybuildstage hello .
CMD ["./hello"]
We will get the following error message:
standard_init_linux.go:211: exec user process caused "no such file or directory"
We’ve seen that error message before, when we tried to run the C program in the scratch image. We saw that the problem came from the lack of dynamic libraries in the scratch image. It looks like the libraries are also missing from the alpine image, then?
Not exactly. Alpine also uses dynamic libraries. After all, one of its design goals is to achieve a small footprint; and static binaries wouldn’t help with that.
But Alpine uses a different standard C library. Instead of of the GNU C library, it uses musl. (I personally pronounce it emm-you-ess-ell, but the official pronounciation is like “mussel” or “muscle”.) This library is smaller, simpler, and safer than the GNU C library. And programs dynamically linked against the GNU C library won’t work with musl, and vice versa.
You might wonder, “if musl is smaller, simpler, and safer, why don’t we all switch to it?”
… Because the GNU C library has a lot of extensions, and some programs do use these extensions; sometimes without even realizing that they’re using non-standard extensions. The musl documentation has a list of functional differences from the GNU C library.
Furthermore, musl is not binary-compatible. A binary compiled for the GNU C library won’t work with musl (except in some very simple cases), meaning that code has to be recompiled (and sometimes tweaked a tiny bit) to work with musl.
TL,DR: using Alpine as the “run” stage will only work if the program has been built for musl, which is the C library used by Alpine.
That being said, it’s relatively easy to build a program for musl. All we have to do is to build it with Alpine itself!
Using Alpine as “build” and “run” stages
We’ve decided to generate a binary linked against musl, so that it can run in the alpine base image. We have two main routes to do that.
- Some official images provide
:alpinetags that should be as close as possible to the normal image, but use Alpine (and musl) instead. - Some official images do not have an
:alpinetag; For those, we need to build an equivalent image ourselves, generally using alpine as a base.
The golang image belongs to the first category: there is a golang:alpine image providing the Go toolchain built on Alpine.
We can build our little Go program with a Dockerfile like this:
FROM golang:alpine
COPY hello.go .
RUN go build hello.go
FROM alpine
COPY --from=0 /go/hello .
CMD ["./hello"]
The resulting image is 7.5 MB. It is admittedly a lot for a program that merely prints “Hello, world!”, but:
- a more complex program wouldn’t be much bigger,
- this image contains a lot of useful tools,
- since it’s based on Alpine, it’s easy and fast to add more tools, in the image or on the spot as needed.
Now, what about our C program? As I write these lines, there is no gcc:alpine image. So we have to start with the alpine image, and install a C compiler. The resulting Dockerfile looks like this:
FROM alpine
RUN apk add build-base
COPY hello.c .
RUN gcc -o hello hello.c
FROM alpine
COPY --from=0 hello .
CMD ["./hello"]
The trick is to install build-base (and not simply gcc) because the gcc package on Alpine would install the compiler, but not all the libraries that we need. Instead, we use build-base, which is the equivalent of the Debian or Ubuntu build-essentials, bringing in compilers, libraries, and tools like make.
Bottom line: when using multi-stage builds, we can use the alpine image as a base to run our code. If our code is a compiled program written in a language using dynamic libraries (which is the case of almost every compiled language that we may use in containers), we will need to generate a binary linked with Alpine’s musl C library. The easiest way to achieve that is to base our build image on top of alpine or another image using Alpine. Many official images offer a tag `:alpine for that purpose.
For our “hello world” program, here are the final results, comparing all the techniques we’ve shown so far.
- Single-stage build using the golang image: 805 MB
- Multi-stage build using golang and ubuntu: 66.2 MB
- Multi-stage build using golang and alpine: 7.6 MB
- Multi-stage build using golang and scratch: 2 MB
That’s a 400x size reduction, or 99.75%. That sounds impressive, but let’s look at the results if we try with a slightly more realistic program that makes use of the net package.
- Single-stage build using the golang image: 810 MB
- Multi-stage build using golang and ubuntu: 71.2 MB
- Multi-stage build using golang:alpine and alpine: 12.6 MB
- Multi-stage build using golang and busybox:glibc: 12.2 MB
- Multi-stage build using golang, CGO_ENABLED=0, and scratch: 7 MB
That’s still a 100x size reduction, a.k.a. 99%. Sweet!
What about Java?
Java is a compiled language, but it runs on the Java Virtual Machine (or JVM). Let’s see what this means for multi-stage builds.
Static or dynamic linking?
Conceptually, Java uses dynamic linking, because Java code will call Java APIs that are provided by the JVM. The code for these APIs is therefore outside of your Java “executable” (typically a JAR or WAR file).
However, these Java libraries are not totally independent from the system libraries. Some Java functions might eventually call system libraries; for instance, when we open a file, at some point the JVM is going to call open(), fopen(), or some variant thereof. You can read that again: the JVM is going to call these functions; so the JVM itself might be dynamically linked with system libraries.
This means that in theory, we can use any JVM to run our Java bytecode; it doesn’t matter if it’s using musl or the GNU C library. So we can build our Java code with any image that has a Java compiler, and then run it with any image that has a JVM.
The Java Class Files Format
In practice, however, the format of Java Class Files (the bytecode generated by the Java compiler) has evolved over time. The bulk of the changes from one Java release to the next are located within the Java APIs. Some changes concern the language itself, like the addition of generics in Java 5. These changes can introduce changes to the format of Java .class Files, breaking compatibility with older versions.
This means that by default, classes compiled with a given version of the Java compiler won’t work with older versions of the JVM. But we can ask the compiler to target an older file format with the -target flag (up to Java 8) or the --release flag (from Java 9). The latter will also select the correct class path, to make sure that if we build code designed to run on e.g. Java 11, we don’t accidentally use libraries and APIs from Java 12 (which would prevent our code from running on Java 11).
(You can read this good blog post about Java Class File Versions if you want to know more about this.)
JDK vs JRE
If you are familiar with the way Java is packaged on most platforms, you probably already know about JDK and JRE.
JRE is the Java Runtime Environment. It contains what we need to run Java applications; namely, the JVM.
JDK is the Java Development Kit. It contains the same thing as the JRE, but it also has what we need to develop (and build) Java applications; namely, the Java compiler.
In the Docker ecosystem, most Java images provide the JDK, so they are suitable to build and run Java code. We will also see some images with a :jre tag (or a tag containing jre somewhere). These are images containing only the JRE, without the full JDK. They are smaller.
What does this mean in terms of multi-stage builds?
We can use the regular images for the build stage, and then a smaller JRE image for the run stage.
java vs openjdk
You might already know this if you’re using Java in Docker; but you shouldn’t use the java official images, because they aren’t receiving updates anymore. Instead, use the openjdk images.
You can also try the amazoncorretto ones (Corretto is Amazon’s fork of OpenJDK, with their extra patches).
Bottom line
Alright, so what should we use? If you’re on the market for small Java images, here are a few good candidates:
openjdk:8-jre-alpine(only 85 MB!)openjdk:11-jre(267 MB) or even openjdk:11-jre-slim (204 MB) if you need a more recent version of Javaopenjdk:14-alpine(338 MB) if you need an even more recent version
Unfortunately, not all combinations are available; i.e. openjdk:14-jre-alpine doesn’t exist (which is sad because it might perhaps be smaller than the -jre and -alpine variants) but there is probably a good reason for that. (If you are aware of that reason, please tell me, I’d love to know!)
Remember that you should build your code to match the JRE version. This blog post explains how to do that in various environments (IDE, Maven, etc.) if you need details.
You want some numbers? I got some numbers for you! I’ve built a trivial “hello world” program in Java:
class hello {
public static void main(String [] args) {
System.out.println("Hello, world!");
}
}
You can find all the Dockerfiles in the minimage GitHub repo, and here are the sizes of the various builds.
- Single-stage build using the
javaimage: 643 MB - Single-stage build using the
openjdkimage: 490 MB - Multi-stage build using
openjdkandopenjdk:jre:479 MB - Single-stage build using the
amazoncorrettoimage: 390 MB - Multi-stage build using
openjdk:11andopenjdk:11-jre: 267 MB - Multi-stage build using
openjdk:8andopenjdk:8-jre-alpine: 85 MB
What about interpreted languages?
If you mostly write code in an interpreted language like Node, Python, or Ruby, you might wonder if you should worry at all about all of this, and if there is any way to optimize image size. It turns out that the answer to both questions is yes!
Alpine with interpreted languages
We can use alpine and other Alpine-based images to run code in our favorite scripting languages. This will always work for code that only uses the standard library, or whose dependencies are “pure”, i.e. written in the same language, without calling into C code and external libraries.
Now, if our code has dependencies on external libraries, things can get more complicated. We will have to install these libraries on Alpine. Depending on the situation, this might be:
- Easy, when the library includes installation instructions for Alpine. It will tell us which Alpine packages to install and how to build the dependencies. This is fairly rare, though, because Alpine isn’t as popular as Debian or Fedora, for instance.
- Average, when the library doesn’t have installation instructions for Alpine, but has instructions for another distro and you can easily figure out which Alpine packages correspond to the other distro’s package.
- Hard, when our dependency is using packages that don’t have Alpine equivalents. Then we might have to build from source, and it will be a whole different story!
That last scenario is precisely the kind of circumstance when Alpine might not help, and might even be counterproductive. If we need to build from source, that means installing a compiler, libraries, headers … This will take extra space on the final image. (Yes, we could use multi-stage builds; but in that specific context, depending on the language, that can be complex, because we need to figure out how to produce a binary package for our dependencies.) Building from source will also take much longer.
There is one particular situation where using Alpine will exhibit all these issues: data science in Python. Popular packages like numpy or pandas are available as pre-compiled Python packages called wheels, but these wheels are tied to a specific C library. (“Oh, no!” you might think, “Not the libraries again!”) This means that they will install fine on the “normal” Python images, but not on the Alpine variants. On Alpine, they will require to install system packages, and in some cases, very lengthy rebuilds. There is a pretty good article dedicated to that problem, explaining how using Alpine can make Python Docker builds 50x slower.
If you read that article, you might think, “whoa, should I stay away from Alpine for Python, then?” I’m not so sure. For data science, probably yes. But for other workloads, if you want to reduce image size, it’s always worth a shot.
:slim images
If we want a compromise between the default images and their Alpine variants, we can check the :slim images. The slim images are usually based on Debian (and on the GNU C library) but they have been optimized for size, by removing a lot of non-essential packages. Sometimes, they might have just what you need; and sometimes, they will lack essential things (like, a compiler!) and installing these things will bring you back closer to the original size; but it’s nice to have the possibility to try and use them.
To give you an idea, here are the sizes of the default, :alpine, and :slim variants for some popular interpreted languages:
Image Size
---------------------------
node 939 MB
node:alpine 113 MB
node:slim 163 MB
python 932 MB
python:alpine 110 MB
python:slim 193 MB
ruby 842 MB
ruby:alpine 54 MB
ruby:slim 149 MB
In the specific case of Python, here are the sizes obtained to install the popular packages matplotlib, numpy, and pandas, on various Python base images:
Image and technique Size
--------------------------------------
python 1.26 GB
python:slim 407 MB
python:alpine 523 MB
python:alpine multi-stage 517 MB
We can see that using Alpine doesn’t help us at all, and even a multi-stage build barely improves the situation. (You can find the relevant Dockerfiles in the minimage repository; they are the ones named Dockerfile.pyds.*.)
Don’t conclude too quickly that Alpine is bad for Python, though! Here are the sizes for a Django application using a large number of dependencies:
Image and technique Size
--------------------------------------
python 1.23 GB
python:alpine 636 MB
python:alpine multi-stage 391 MB
(And in that specific case, I gave up on using the :slim image because it required installing too many extra packages.)
So as you can see, it’s not always clear cut. Sometimes, :alpine will give better results, and sometimes :slim will do it. If we really need to optimize the size of our images, we need to try both and see what happens. Over time, we will gather experience and get a feel of which variant is appropriate for which applications.
Multi-stage with interpreted languages
What about multi-stage builds?
They will be particularly useful when we generate any kind of asset.
For instance, you have a Django application (probably using some python base image) but you minify your Javascript with UglifyJS and your CSS with Sass. The naive approach would be to include all that jazz in your image, but the Dockerfile would become complex (because we’d be installing Node in a Python image) and the final image would be of course very big. Instead, we can use multiple stages: one using node to minify your assets, and one using python for the app itself, bringing in the JS and CSS assets from the first stages.
This is also going to result in better build times, since changes in the Python code won’t always result in a rebuild of the JS and CSS (and vice versa). In that specific case, I would even recommend to use two separate stages for JS and CSS, so that changing one doesn’t trigger a rebuild of the other.
What about Rust?
I am very curious about Rust, a modern programming language initially designed at Mozilla, and with a growing popularity in the web and infrastructure space. So I was wondering what kind of behavior to expect as far as Docker images are involved.
It turns out that Rust generates binaries dynamically linked with the C library. So binaries built with the rust image will run with usual base images like debian, ubuntu, fedora, etc., but will not work with busybox:glibc. This is because the binaries are linked with libdl, which is not included in busybox:glibc at the moment.
However, there is a rust:alpine image, and the generated binaries work perfectly well with alpine as a base.
I wondered if Rust could produce static binaries. The Rust documentation explains how to do it. On Linux, this is done by building a special version of the Rust compiler, and it requires musl. Yes, the same musl used by Alpine. If you want to obtain minimal images with Rust, it should be fairly easy by following the instructions in the documentation, then drop the resulting binaries in a scratch image.
Conclusion
In the first two part of this series, we covered the most common methods to optimize Docker image size, and we saw how they applied to various languages, compiled or interpreted.
In the last part, we will talk about a few more. We will see how standardizing on a specific base image can reduce not only image size, but also I/O and memory usage. We will mention a few techniques that are not specific to containers, but that can always be useful. And we will evoke more exotic builders, for the sake of completeness.



