

Series Index
Why and What
Projects, Dependencies and Gopls
Minimal Version Selection
Mirrors, Checksums and Athens
Gopls Improvements
Vendoring
Introduction
Modules provide an integrated solution for three key problems that have been a pain point for developers since Go’s initial release:
- Ability to work with Go code outside of the GOPATH workspace.
- Ability to version a dependency and identify the most compatible version to use.
- Ability to manage dependencies natively using the Go tooling.
With the release of Go 1.13, these three problems are a thing of the past. It has taken a lot of engineering effort from the Go team over the past 2 years to get everyone here. In this post, I will focus on the transition from GOPATH to modules and the problems modules are solving. Along the way, I will provide just enough of the semantics so you can have a better understanding of how modules work at a high level. Maybe more importantly, why they work the way they do.
GOPATH
The use of GOPATH to provide the physical location on disk where your Go workspace exists has served Go developers well. Unfortunately, it’s been a bottleneck for non Go developers who might need to work on a Go project from time to time and don’t have a Go workspace setup. One problem the Go team wanted to solve was allowing a Go repository (repo) to be cloned anywhere on disk (outside of GOPATH) and have the tooling be able to locate, build and test the code.
Figure 1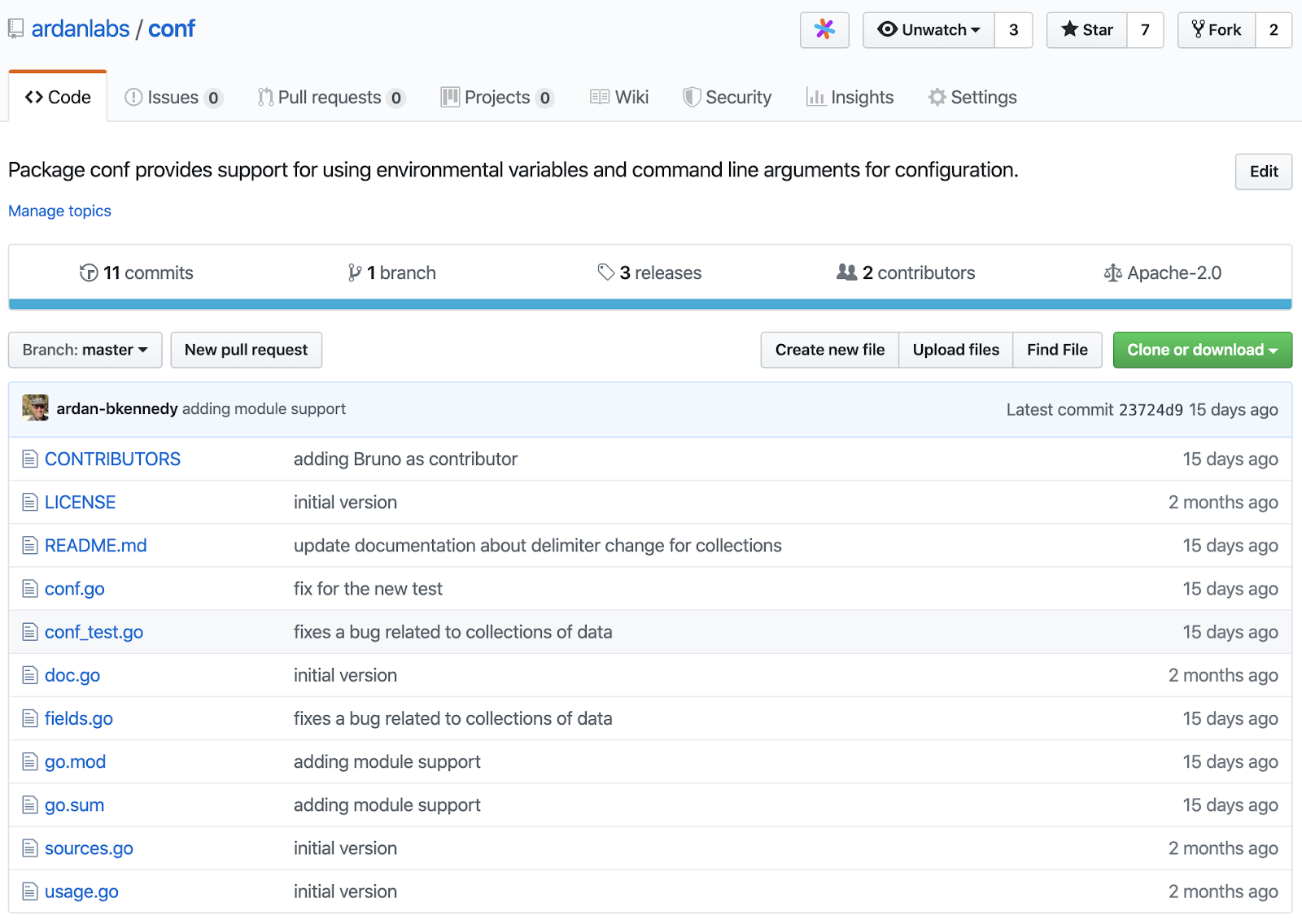
Figure 1 shows the GitHub repo for the conf package. This repo represents a single package that provides support for handling configuration in applications. Before modules, if you wanted to use this package, you would use go get to clone a copy of the repo inside your GOPATH using the canonical name of the repo as its exact location on disk. The canonical name being a combination of the root of the remote repository and the name for the repo.
As an example before modules, if you ran go get github.com/ardanlabs/conf, the code would be cloned on disk at $GOPATH/src/github.com/ardanlabs/conf. Thanks to GOPATH and knowing the canonical name for the repo, the Go tooling can find the code regardless of where any developer chooses to place the workspace on their machine.
Resolving Imports
Listing 1
github.com/ardanlabs/conf/blob/master/conf_test.go
01 package conf_test
02
03 import (
...
10 "github.com/ardanlabs/conf"
...
12 )
Listing 1 shows a partial version of the import section of the conf_test.go test file from the conf repo. When a test uses the _test naming convention in the package name (like you see on line 01) this means the test code exists in a different package from the code being tested and the test code must import the package like any external user of the package. You can see how this test file imports the conf package on line 10 using the canonical name of the repo. Thanks to the GOPATH mechanics, this import can be resolved on disk and the tooling can locate, build and test the code.
How will any of this work when GOPATH no longer exists and the folder structure doesn’t match the canonical name of the repo any longer?
Listing 2
import "github.com/ardanlabs/conf"
// GOPATH mode: Physical location on disk matches the GOPATH
// and Canonical name of the repo.
$GOPATH/src/github.com/ardanlabs/conf
// Module mode: Physical location on disk doesn’t represent
// the Canonical name of the repo.
/users/bill/conf
Listing 2 shows the problem of cloning the conf repo in any location you wish. When the developer has the option to clone the code anywhere they want, all the information to resolve the same import back to physical disk is gone.
The solution to this problem was to have a special file that contained the canonical name for the repo. The location of this file on disk is used as a substitute for GOPATH and having the canonical name for the repo defined inside the file allows the Go tooling to resolve the import, regardless of where the repo is cloned.
It was decided to name this special file go.mod and the canonical name for the repo defined inside the file would represent this new entity called a module.
Listing 3
github.com/ardanlabs/conf/blob/v1.1.0/go.mod
01 module github.com/ardanlabs/conf
02
...
06
Listing 3 shows the first line of the go.mod file inside the conf repo. This line defines the name of the module which represents the canonical name developers are expected to use for referencing any code inside the repo. Now it doesn’t matter where the repo is cloned since the Go tooling can use the module file location and module name to resolve any internal import, such as the import in the test file.
With the concept of a module allowing code to be cloned anywhere on disk, the next problem to solve is support for code to be bundled together and versioned.
Bundling and Versioning
Most VCSs provide the ability to tag a label to your repo at any commit point. These tags are typically used to release new features (v1.0.0, v2.3.8, etc.) and are typically treated as immutable.
Figure 2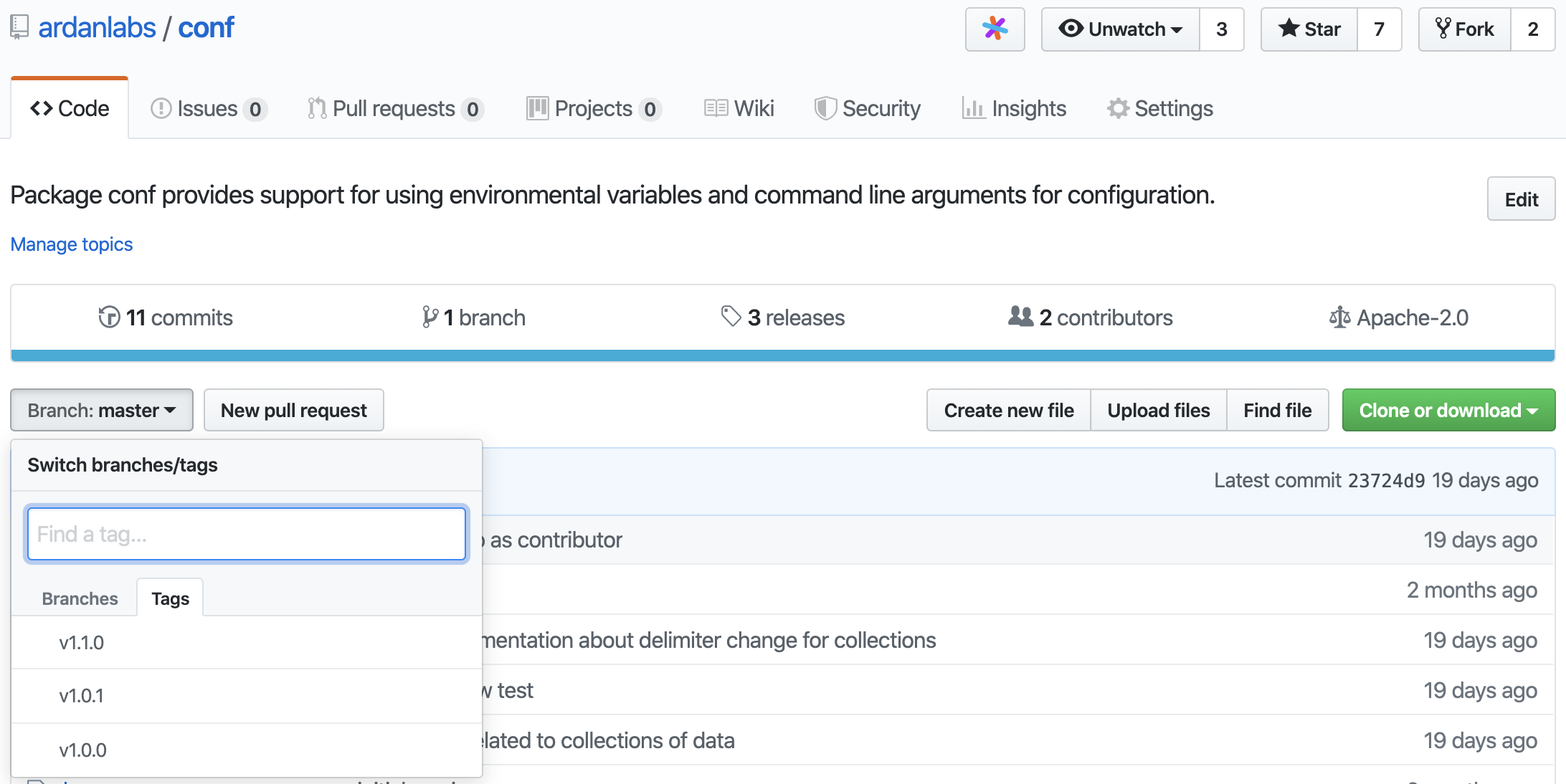
Figure 2 shows that the author of the conf package has tagged three distinct versions of the repo. These tagged versions adhere to the Semantic Versioning format.
Using VCS tooling, a developer can clone any particular version of the conf package to disk by referencing a specific tag. However, there are a couple of questions that need to be answered first:
- Which version of the package should I use?
- How do I know which version is compatible with all the code I am writing and using?
Once you answer those two questions, you have a third question to answer:
- Where do I clone the repo so the Go tooling can find and access it?
Then it gets worse. You can’t use a version of the conf package in your own project unless you also clone all the repos for the packages that conf depends on. This is a problem for all of your project’s transitive dependencies.
When operating in GOPATH mode, the solution was to use go get to identify and clone all the repos for all the dependencies into your GOPATH workspace. However, this wasn’t a perfect solution since go get only knows how to clone and update the latest code from the master branch for each dependency. Pulling code from the master branch for each dependency might be fine when you write your initial code. Eventually after a few months (or years) of dependencies evolving independently, the dependencies’ latest master code is likely to no longer be compatible with your project. This is because your project is not respecting the version tags so any upgrade might contain a breaking change.
When operating in the new module mode, the option for go get to clone the repos for all the dependencies into a single well defined workspace is no longer preferred. Plus, you need to find a way of referencing a compatible version of each dependency that would work for the entirety of the project. Then there is supporting the use of different major semantic versions of the same dependency within your project incase your dependencies are importing different major versions of the same package.
Although some solutions to these problems already existed in the form of community-developed tooling (dep, godep, glide, …), Go needed an integrated solution. The solution was to reuse the module file to maintain a list of direct and sometimes indirect dependencies by version. Then treat any given version of a repo as a single immutable bundle of code. This versioned immutable bundle is called a module.
Integrated Solution
Figure 3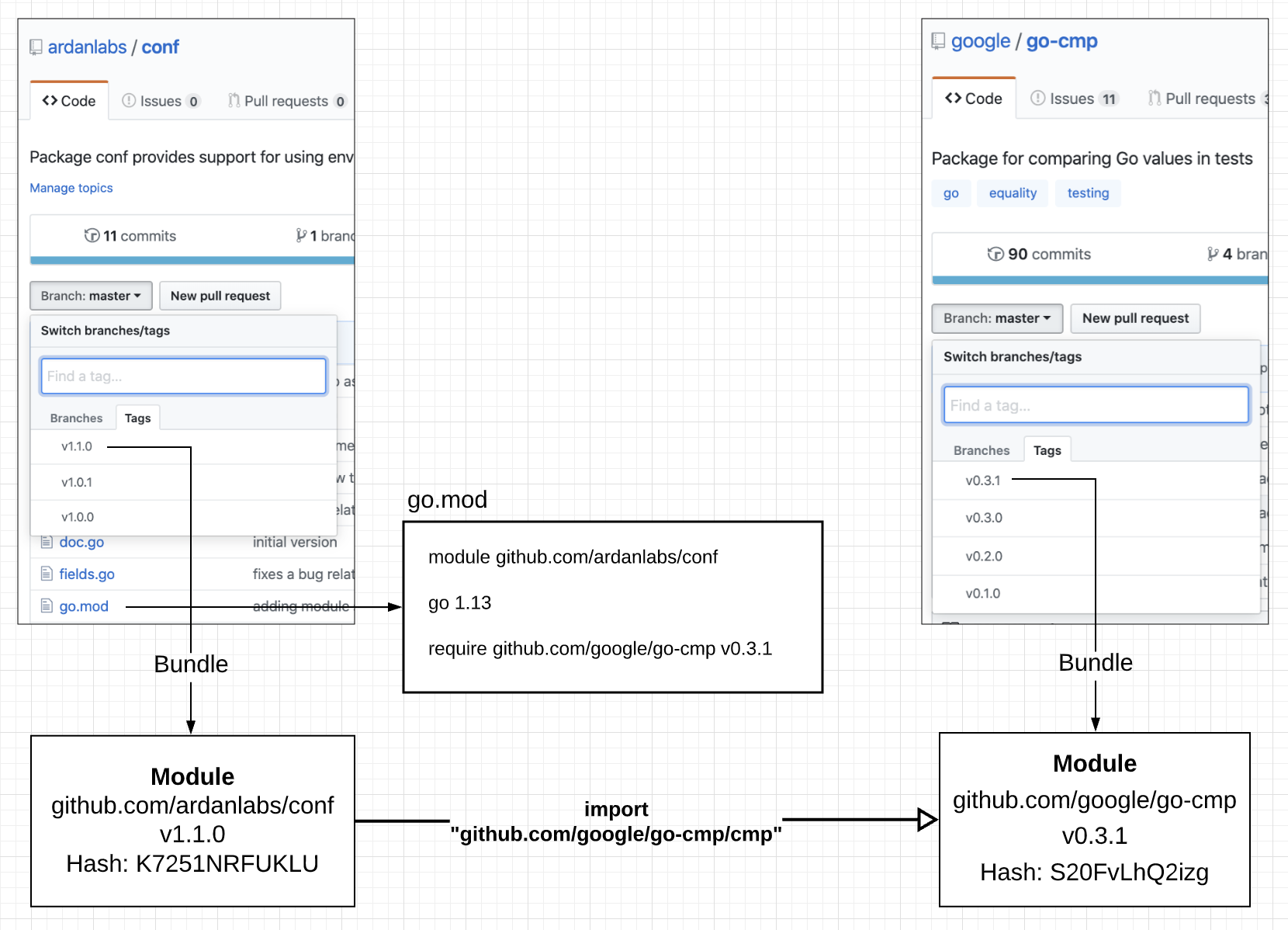
Figure 3 shows the relationship between a repo and a module. It shows how an import can reference a package that is stored inside a given version of a module. In this case, code inside module conf at version 1.1.0 can import the package cmp from module go-cmp at version 0.3.1. Since the dependency information is listed inside the conf module (via the module file), the Go tooling can fetch the selected version of any module so a successful build can take place.
Once you have modules, a lot of engineering opportunities begin to present themselves:
- You could provide support (with some exceptions) to build, retain, authenticate, validate, fetch, cache, and reuse modules for use by Go developers all over the world.
- You could build proxy servers that would front the different VCSs and provide some of the aforementioned support.
- You could verify a module (for any given version) always contains the same exact code known to exist in the module, regardless of how many times it’s built, where it’s fetched from, and by whom.
The best part about what could be supported with modules, is that the Go team engineered much of this support already in version 1.13 of Go.
Conclusion
This post attempted to lay down the groundwork for understanding what a module is and how the Go team ended up with this solution. There is still much left to talk about, such as:
- How is a particular version of a module selected for use?
- How is a module file structured and what options do you have to control module selection?
- How is a module built, fetched, and cached locally to disk to resolve imports?
- How is a module validated for the social contract of Semantic Versioning?
- How should modules be used in your own projects and what are the best practices?
In future posts, I plan to provide an understanding to these questions and much more. For now, make sure you understand the relationship between repos, packages and modules. If you have any questions, don’t hesitate to find me on Slack. There is a great channel called #modules where people are always ready to help.
Module Documentation
There is a lot of Go documentation that has been written. Here are some of the posts published by the Go team.
Modules The Wiki
1.13 Go Release Notes
Go Blog: Module Mirror and Checksum Database Launched
Go Blog: Publishing Go Modules
Proposal: Secure the Public Go Module Ecosystem
GopherCon 2019: Katie Hockman - Go Module Proxy: Life of a Query



