

Originally published in 2019, this article is part two of a three-part series exploring Go’s garbage collector. Though the Go runtime has continued to evolve, the performance principles covered here remain highly relevant today. This installment focuses on practical techniques for analyzing and reducing garbage collection (GC) overhead in real-world Go applications. It walks through how to interpret GC traces using GODEBUG=gctrace=1 and uncover allocation hotspots with pprof, with a clear message: reducing unnecessary allocations, especially in tight loops, has a direct and measurable impact on latency and throughput. Whether you’re optimizing high-performance services or just becoming GC-aware, the insights here are as applicable now as ever.
Prelude
This is the second post in a three part series that will provide an understanding of the mechanics and semantics behind the garbage collector in Go. This post focuses on how to generate GC traces and interpret them.
Index of the three part series:
- Garbage Collection In Go : Part I - Semantics
- Garbage Collection In Go : Part II - GC Traces
- Garbage Collection In Go : Part III - GC Pacing
Introduction
In the first post, I took the time to describe the behavior of the garbage collector and show the latencies that the collector inflicts on your running application. I shared how to generate and interpret a GC trace, showed how the memory on the heap is changing, and explained the different phases of the GC and how they affect latency cost.
The final conclusion of that post was, if you reduce stress on the heap you will reduce the latency costs and therefore increase the application’s performance. I also made a point that it’s not a good strategy to decrease the pace at which collections start, by finding ways to increase the time between any two collections. A consistent pace, even if it’s quick, will be better at keeping the application running at top performance.
In this post, I will walk you through running a real web application and show you how to generate GC traces and application profiles. Then I will show you how to interpret the output from these tools so you can find ways to improve the performance of your applications.
Running The Application
Look at this web application that I use in the Go training.
Figure 1
https://github.com/ardanlabs/gotraining/tree/master/topics/go/profiling/project
Figure 1 shows what the application looks like. This application downloads three sets of rss feeds from different news providers and allows the user to perform searches. After building the web application, the application is started.
Listing 1
$ go build
$ GOGC=off ./project > /dev/null
Listing 1 show how the application is started with the GOGC variable set to off, which turns the garbage collection off. The logs are redirected to the /dev/null device. With the application running, requests can be posted into the server.
Listing 2
$ hey -m POST -c 100 -n 10000 "http://localhost:5000/search?term=topic&cnn=on&bbc=on&nyt=on"
Listing 2 shows how 10k requests using 100 connections are run through the server using the hey tool. Once all the requests are sent through the server, this produces the following results.
Figure 2
Figure 2 shows a visual representation of processing 10k requests with the garbage collector off. It took 4,188ms to process the 10k requests which resulted in the server processing ~2,387 requests per second.
Turning on Garbage Collection
What happens when the garbage collection is turned on for this application?
Listing 3
$ GODEBUG=gctrace=1 ./project > /dev/null
Listing 3 shows how the application is started to see GC traces The GOGC variable is removed and replaced with the GODEBUG variable. The GODEBUG is set so the runtime generates a GC trace every time a collection happens. Now the same 10k requests can be run through the server again. Once all the requests are sent through the server, there are GC traces and information provided by the hey tool that can be analyzed.
Listing 4
$ GODEBUG=gctrace=1 ./project > /dev/null
gc 3 @3.182s 0%: 0.015+0.59+0.096 ms clock, 0.19+0.10/1.3/3.0+1.1 ms cpu, 4->4->2 MB, 5 MB goal, 12 P
.
.
.
gc 2553 @8.452s 14%: 0.004+0.33+0.051 ms clock, 0.056+0.12/0.56/0.94+0.61 ms cpu, 4->4->2 MB, 5 MB goal, 12 P
Listing 4 shows a GC trace of the third and last collection from the run. I’m not showing the first two collections since the load was sent through the server after those collection took place. The last collection shows that it took 2551 collections (subtract the first two collections since they don’t count) to process the 10k requests.
Here is a break-down of each section in the trace.
Listing 5
gc 2553 @8.452s 14%: 0.004+0.33+0.051 ms clock, 0.056+0.12/0.56/0.94+0.61 ms cpu, 4->4->2 MB, 5 MB goal, 12 P
gc 2553 : The 2553 GC runs since the program started
@8.452s : Eight seconds since the program started
14% : Fourteen percent of the available CPU so far has been spent in GC
// wall-clock
0.004ms : STW : Write-Barrier - Wait for all Ps to reach a GC safe-point.
0.33ms : Concurrent : Marking
0.051ms : STW : Mark Term - Write Barrier off and clean up.
// CPU time
0.056ms : STW : Write-Barrier
0.12ms : Concurrent : Mark - Assist Time (GC performed in line with allocation)
0.56ms : Concurrent : Mark - Background GC time
0.94ms : Concurrent : Mark - Idle GC time
0.61ms : STW : Mark Term
4MB : Heap memory in-use before the Marking started
4MB : Heap memory in-use after the Marking finished
2MB : Heap memory marked as live after the Marking finished
5MB : Collection goal for heap memory in-use after Marking finished
// Threads
12P : Number of logical processors or threads used to run Goroutines.
Listing 5 shows the actual numbers from the last collection. Thanks to hey, these are the performance results of the run.
Listing 6
Requests : 10,000
------------------------------------------------------
Requests/sec : 1,882 r/s - Hey
Total Duration : 5,311ms - Hey
Percent Time in GC : 14% - GC Trace
Total Collections : 2,551 - GC Trace
------------------------------------------------------
Total GC Duration : 744.54ms - (5,311ms * .14)
Average Pace of GC : ~2.08ms - (5,311ms / 2,551)
Requests/Collection : ~3.98 r/gc - (10,000 / 2,511)
Listing 6 shows the results. The following provides more of a visual of what happened.
Figure 3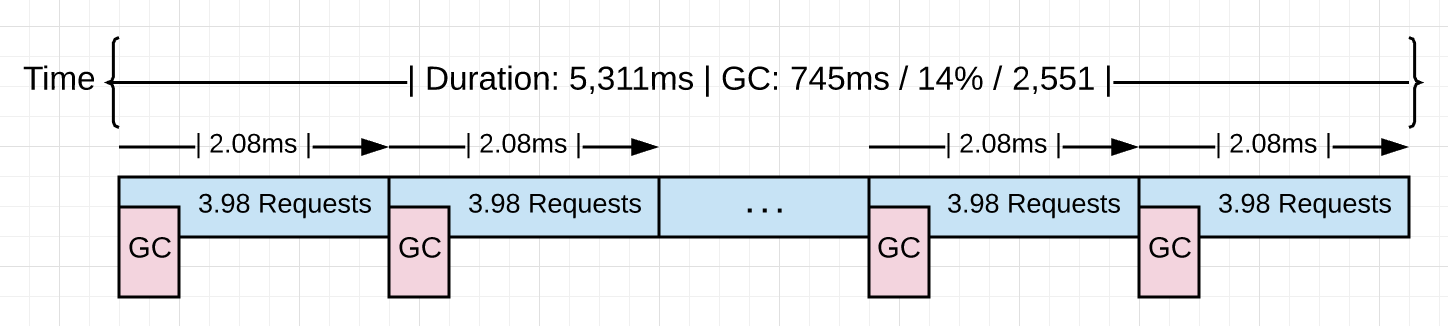
Figure 3 shows what happened visually. When the collector is turned on it had to run ~2.5k times to process the same 10k requests. Each collection on average is starting at a pace of ~2.0ms and running all these collections added an extra ~1.1 seconds of latency.
Figure 4
Figure 4 shows a comparison of the two runs of the application so far.
Reduce Allocations
It would be great to get a profile of the heap and see if there are any non-productive allocations that can be removed.
Listing 7
go tool pprof http://localhost:5000/debug/pprof/allocs
Listing 7 show the use of the pprof tool calling the /debug/pprof/allocs endpoint to pull a memory profile from the running application. That endpoint exists because of the following code.
Listing 8
import _ "net/http/pprof"
go func() {
http.ListenAndServe("localhost:5000", http.DefaultServeMux)
}()
Listing 8 shows how to bind the /debug/pprof/allocs endpoint to any application. Adding the import to net/http/pprof binds the endpoint to the default server mux. Then using http.ListenAndServer with the http.DefaultServerMux constant makes the endpoint available.
Once the profiler starts, the top command can be used to see the top 6 functions that are allocating the most.
Listing 9
(pprof) top 6 -cum
Showing nodes accounting for 0.56GB, 5.84% of 9.56GB total
Dropped 80 nodes (cum <= 0.05GB)
Showing top 6 nodes out of 51
flat flat% sum% cum cum%
0 0% 0% 4.96GB 51.90% net/http.(*conn).serve
0.49GB 5.11% 5.11% 4.93GB 51.55% project/service.handler
0 0% 5.11% 4.93GB 51.55% net/http.(*ServeMux).ServeHTTP
0 0% 5.11% 4.93GB 51.55% net/http.HandlerFunc.ServeHTTP
0 0% 5.11% 4.93GB 51.55% net/http.serverHandler.ServeHTTP
0.07GB 0.73% 5.84% 4.55GB 47.63% project/search.rssSearch
Listing 9 shows how at the bottom of the list, the rssSearch function appears. This function allocated 4.55GB of the 5.96GB to date. Next, it’s time to inspect the details of the rssSearch function using the list command.
Listing 10
(pprof) list rssSearch
Total: 9.56GB
ROUTINE ======================== project/search.rssSearch in project/search/rss.go
71.53MB 4.55GB (flat, cum) 47.63% of Total
. . 117: // Capture the data we need for our results if we find ...
. . 118: for _, item := range d.Channel.Items {
. 4.48GB 119: if strings.Contains(strings.ToLower(item.Description), strings.ToLower(term)) {
48.53MB 48.53MB 120: results = append(results, Result{
. . 121: Engine: engine,
. . 122: Title: item.Title,
. . 123: Link: item.Link,
. . 124: Content: item.Description,
. . 125: })
Figure 10 shows the listing and the code. Line 119 sticks out as the bulk of the allocations.
Listing 11
. 4.48GB 119: if strings.Contains(strings.ToLower(item.Description), strings.ToLower(term)) {
Listing 11 shows the line of code in question. That line alone accounts for 4.48GB of the 4.55GB of memory that function has allocated to date. Next, it’s time to review that line of code to see what can be done if anything.
Listing 12
117 // Capture the data we need for our results if we find the search term.
118 for _, item := range d.Channel.Items {
119 if strings.Contains(strings.ToLower(item.Description), strings.ToLower(term)) {
120 results = append(results, Result{
121 Engine: engine,
122 Title: item.Title,
123 Link: item.Link,
124 Content: item.Description,
125 })
126 }
127 }
Listing 12 shows how that line of code is in a tight loop. The calls to strings.ToLower are creating allocations since they create new strings which will need to allocate on the heap. Those calls to strings.ToLower are unnecessary since those calls can be done outside the loop.
Line 119 can be changed to remove all those allocations.
Listing 13
// Before the code change.
if strings.Contains(strings.ToLower(item.Description), strings.ToLower(term)) {
// After the code change.
if strings.Contains(item.Description, term) {
Note: The other code changes you don’t see is the call to make the Description lower before the feed is placed into the cache. The news feeds are cached every 15 minutes. The call to make the term lower is done right outside the loop.
Listing 13 shows how the called to strings.ToLower are removed. The project is built again with these new code changes and the 10k requests are run through the server again.
Listing 14
$ go build
$ GODEBUG=gctrace=1 ./project > /dev/null
gc 3 @6.156s 0%: 0.011+0.72+0.068 ms clock, 0.13+0.21/1.5/3.2+0.82 ms cpu, 4->4->2 MB, 5 MB goal, 12 P
.
.
.
gc 1404 @8.808s 7%: 0.005+0.54+0.059 ms clock, 0.060+0.47/0.79/0.25+0.71 ms cpu, 4->5->2 MB, 5 MB goal, 12 P
Listing 14 shows how it now took 1402 collections to process the same 10k requests after that code change. These are the full results of both runs.
Listing 15
With Extra Allocations Without Extra Allocations
======================================================================
Requests : 10,000 Requests : 10,000
----------------------------------------------------------------------
Requests/sec : 1,882 r/s Requests/sec : 3,631 r/s
Total Duration : 5,311ms Total Duration : 2,753 ms
Percent Time in GC : 14% Percent Time in GC : 7%
Total Collections : 2,551 Total Collections : 1,402
----------------------------------------------------------------------
Total GC Duration : 744.54ms Total GC Duration : 192.71 ms
Average Pace of GC : ~2.08ms Average Pace of GC : ~1.96ms
Requests/Collection : ~3.98 r/gc Requests/Collection : 7.13 r/gc
Listing 15 shows the results compared to the last results. The following provides more of a visual of what happened.
Figure 5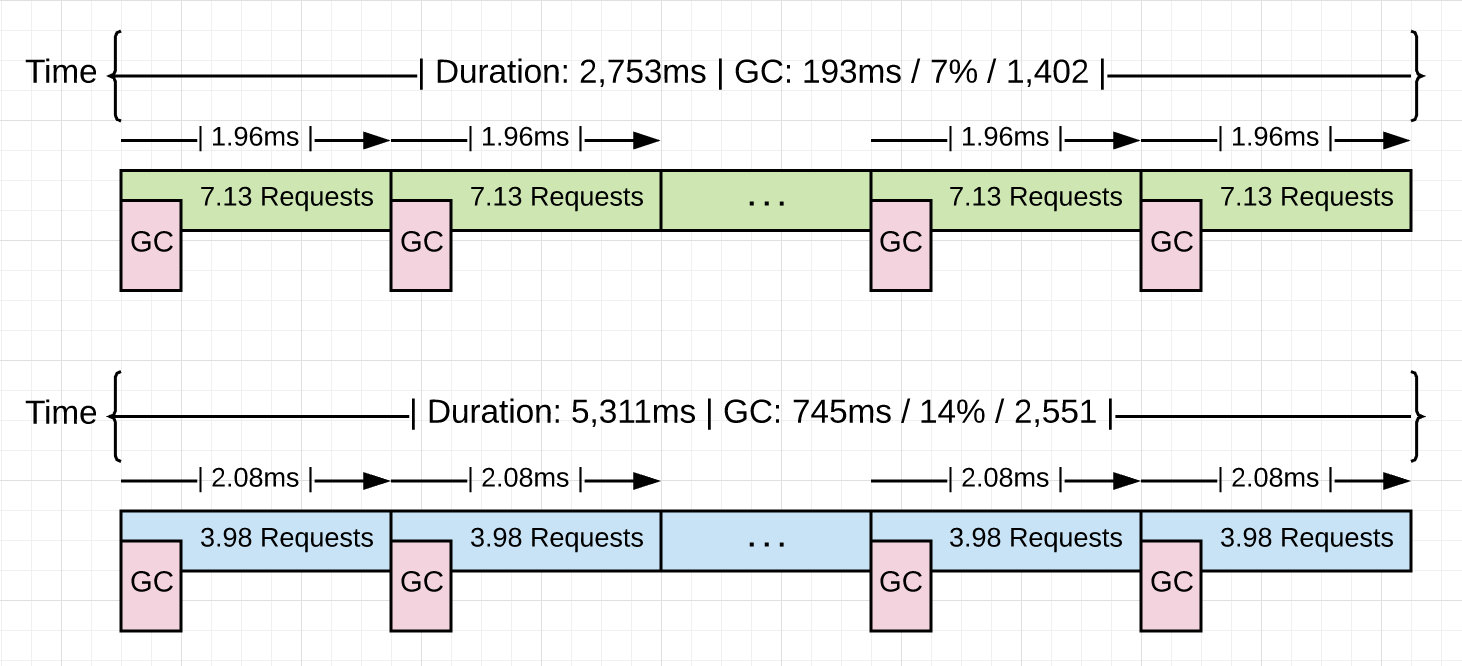
Figure 5 shows what happened visually. This time the collector ran 1149 times less (1,402 vs 2,551) to process the same 10k requests. That resulted in reducing the percent of total GC time down from 14% to 7%. That allowed the application to run 48% faster with %74 less time in collection.
Figure 6
Figure 6 shows a comparison of all the different runs of the application. I included a run of the optimized code running without the garbage collector to be complete.
What We Learned
As I stated in the last post, being sympathetic with the collector is about reducing stress on the heap. Remember, stress can be defined as how fast the application is allocating all available memory on the heap within a given amount of time. When stress is reduced, the latencies being inflicted by the collector will be reduced. It’s the latencies that are slowing down your application.
It’s not about slowing down the pace of collection. It’s really about getting more work done between each collection or during the collection. You affect that by reducing the amount or the number of allocations any piece of work is adding to the heap.
Listing 16
With Extra Allocations Without Extra Allocations
======================================================================
Requests : 10,000 Requests : 10,000
----------------------------------------------------------------------
Requests/sec : 1,882 r/s Requests/sec : 3,631 r/s
Total Duration : 5,311ms Total Duration : 2,753 ms
Percent Time in GC : 14% Percent Time in GC : 7%
Total Collections : 2,551 Total Collections : 1,402
----------------------------------------------------------------------
Total GC Duration : 744.54ms Total GC Duration : 192.71 ms
Average Pace of GC : ~2.08ms Average Pace of GC : ~1.96ms
Requests/Collection : ~3.98 r/gc Requests/Collection : 7.13 r/gc
Listing 16 shows the results of the two versions of the applications with the garbage collection on. It is clear that removing the 4.48GB of allocations made the application run faster. What is interesting, is the average pace of each collection (for both versions) is virtually the same, at around ~2.0ms. What fundamentally changed between these two versions is the amount of work that is getting done between each collection. The application went from 3.98 r/gc to 7.13 r/gc. That is a 79.1% increase in the amount of work getting done.
Getting more work done between the start of any two collections helped to reduce the number of collections that were needed from 2,551 to 1,402, a 45% reduction. The application saw a %74 reduction in total GC time from 745ms to 193ms with a change from 14% to 7% of total time for each respective version being in collection. When you run the optimized version of the application without garbage collection, the difference in performance is only 13%, with the application taking 2,753ms down to 2,398ms.
Conclusion
If you take the time to focus on reducing allocations, you are doing what you can as a Go developer to be sympathetic with the garbage collector. You are not going to write zero allocation applications so it’s important to recognize the difference between allocations that are productive (those helping the application) and those that are not productive (those hurting the application). Then put your faith and trust in the garbage collector to keep the heap healthy and your application running consistently.
Having a garbage collector is a nice tradeoff. I will take the cost of garbage collection so I don’t have the burden of memory management. Go is about allowing you as a developer to be productive while still writing applications that are fast enough. The garbage collector is a big part of making that a reality. In the next post, I will share another program that shows how well the collector can analyze your Go applications and find the optimal collection path.



