

Introduction
One day I was talking to Damian Gryski in Slack about some performance improvements he made to his go-metro package. When I first looked at the changes I was completely confused how this could have any effect on the performance of the code. I felt the code was more readable, but more performant? I didn’t see it.
Then Damian started to talk to me about a compiler optimization called Bounds Check Elimination or BCE. The idea behind BCE is to give the compiler hints that index-based memory access is guaranteed to be safe and therefore the compiler didn’t have to add extra code to check the memory access at runtime. The safe elimination of these integrity checks can help improve performance.
I want to stress that this is a micro optimization that you can look at after you get your program working. Unless you really need to shave nanoseconds of time off your algorithms, there are probably bigger fish to fry. In Damian’s case, every nanosecond counted.
Damian’s Code Changes
Damian’s code changes can be found on this commit. Here is a picture of that commit and his benchmarks.
Figure 1
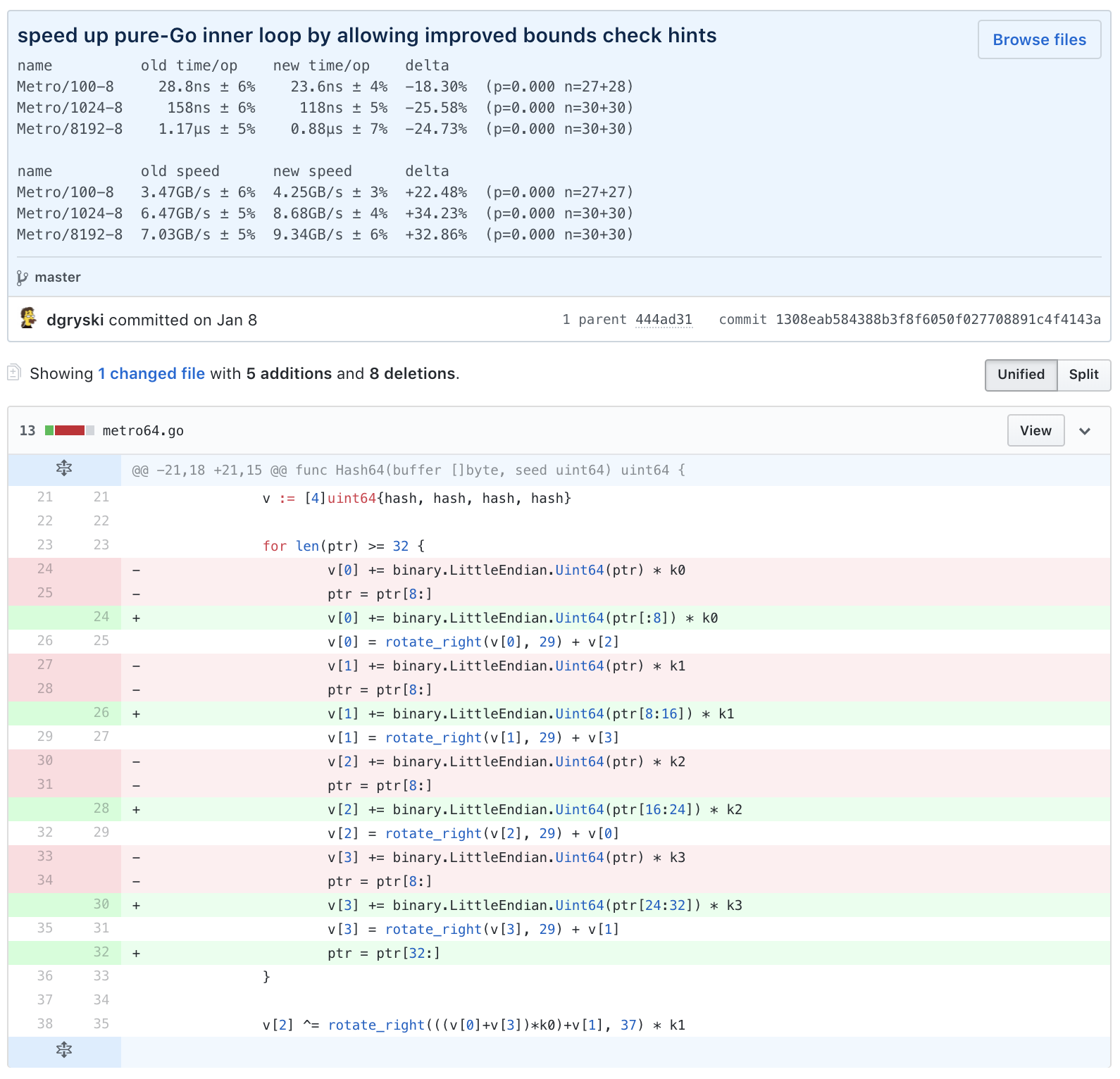
If you are new to BCE like I was when Damian showed me this for the first time, you might be confused how those code changes affected performance. The SSA portion of the compiler can show us the decisions it’s making with code related to bounds checks.
BCE Examples
It didn’t make sense for me to reproduce the great work by these authors. Read these posts to learn more and see interesting Go coding examples. Then come back to finish this post.
https://go101.org/article/bounds-check-elimination.html
gBounds Checking Elimination
Utilizing the Go 1.7 SSA Compiler
Damian’s Code
Start with the original code that was not optimized and caused the compiler to add bounds checks.
Listing 1
https://play.golang.org/p/L3DOUNaQkD1
17 if len(ptr) >= 32 {
18 v := [4]uint64{hash, hash, hash, hash}
19
20 for len(ptr) >= 32 {
21 v[0] += binary.LittleEndian.Uint64(ptr) * k0
22 ptr = ptr[8:]
23 v[0] = rotateRight(v[0], 29) + v[2]
24 v[1] += binary.LittleEndian.Uint64(ptr) * k1
25 ptr = ptr[8:]
26 v[1] = rotateRight(v[1], 29) + v[3]
27 v[2] += binary.LittleEndian.Uint64(ptr) * k2
28 ptr = ptr[8:]
29 v[2] = rotateRight(v[2], 29) + v[0]
30 v[3] += binary.LittleEndian.Uint64(ptr) * k3
31 ptr = ptr[8:]
32 v[3] = rotateRight(v[3], 29) + v[1]
33 }
34 }
If you run the build command with the SSA based BCE check flags, you will see a bounds check is needed to be added on three lines of code.
Listing 2
$ go build -gcflags="-d=ssa/check_bce/debug=1"
# github.com/.../.../.../go/metro.go
./temp.go:24:38: Found IsInBounds
./temp.go:27:38: Found IsInBounds
./temp.go:30:38: Found IsInBounds
These are the lines that have the extra code for checking out of bounds memory access.
Listing 3
24 v[1] += binary.LittleEndian.Uint64(ptr) * k1
27 v[2] += binary.LittleEndian.Uint64(ptr) * k2
30 v[3] += binary.LittleEndian.Uint64(ptr) * k3
These lines are deceiving and the real reason for the bounds checks.
Listing 4
22 ptr = ptr[8:]
25 ptr = ptr[8:]
28 ptr = ptr[8:]
Once the slice header is reset from those lines above, information about whether the slice access is in bounds on lines 24, 27 and 30 are lost to the compiler. A slice operation with no upper bound is creating an unknown situation.
Look at the code changes Damian made to remove all the bounds checks.
Listing 5
https://play.golang.org/p/Htr01P6N6e2
17 if len(ptr) >= 32 {
18 v := [4]uint64{hash, hash, hash, hash}
19
20 for len(ptr) >= 32 {
21 v[0] += binary.LittleEndian.Uint64(ptr[:8]) * k0
22 v[0] = rotateRight(v[0], 29) + v[2]
23 v[1] += binary.LittleEndian.Uint64(ptr[8:16]) * k1
24 v[1] = rotateRight(v[1], 29) + v[3]
25 v[2] += binary.LittleEndian.Uint64(ptr[16:24]) * k2
26 v[2] = rotateRight(v[2], 29) + v[0]
27 v[3] += binary.LittleEndian.Uint64(ptr[24:32]) * k3
28 v[3] = rotateRight(v[3], 29) + v[1]
29 ptr = ptr[32:]
30 }
31 }
Outside of the fact that there are now less lines of code, notice how all of the slice operations have an upper bound. Those upper bounds are within the range of the condition on line 20.
Listing 6
20 for len(ptr) >= 32 {
This line of code is helping the compiler know the remaining code inside the if statement is now within a range that must be valid. How brilliant is the Go compiler?
Issues
These are issues that are related to Damian’s code changes.
This issue talks about fixes to the compiler to handle simple math operations to help with BCE optimization:
cmd/compile: bounds check elimination for len(x) - 1
This issue has a fix in version 1.11 for Damian’s original code which would have meant he didn’t have to make these changes:
cmd/compile: bounds check elimination for if len(x) > 32 { ...; x = x[8:]; ... }
Conclusion
People are quick to say that the Go language is simple and mundane. It’s a tribute to the language that it appears like this on the surface. In the end, it’s strong and forward-thinking engineering that has allowed this impression to seem like reality. Underneath the surface so much is happening to help our software have integrity and be as optimized as possible while not losing compiler speed. BCE optimization is just one of many other optimizations the compiler is performing.



