

Prelude
If you want to put this post in some better context, I suggest reading the following series of posts, which lay out some other fundamental and relevant design principles:
- Language Mechanics On Stacks And Pointers
- Language Mechanics On Escape Analysis
- Language Mechanics On Memory Profiling
- Design Philosophy On Data And Semantics
In particular, the idea of value and pointer semantics is everywhere in the Go programming language. As stated in those earlier posts, semantic consistency is critical for integrity and readability. It allows developers to maintain a strong mental model of a code base as it continues to grow. It also helps to minimize mistakes, side effects, and unexpected behavior.
Introduction
In this post, I will explore how the interface in Go provides both a value and pointer semantic form. I will teach the associated language mechanics and show you the depth of these semantics. Then, I will show how the compiler attempts to intercede for you when you are mixing these semantics in a dangerous way.
Language Mechanics
An interface can store its own copy of a value (value semantics), or a value can be shared with the interface by storing a copy of the value’s address (pointer semantics). This is where the value/pointer semantics come in for interfaces. This piece of code shows you how those semantics work.
https://play.golang.org/p/RfXlaRjRFr
Listing 1
01 package main
02
03 import "fmt"
04
05 type printer interface {
06 print()
07 }
08
09 type user struct {
10 name string
11 }
12
13 func (u user) print() {
14 fmt.Println("User Name:", u.name)
15 }
16
17 func main() {
18 u := user{"Bill"}
19
20 entities := []printer{
21 u,
22 &u,
23 }
24
25 u.name = "Bill_CHG"
26
27 for _, e := range entities {
28 e.print()
29 }
30 }
In listing 1, the code declares an interface named printer on line 05 with one act of behavior called print. Then, a concrete type named user is declared on line 09 that implements the printer interface using value semantics on line 13.
In the main function, a user value is created on line 18 and initialized with the name Bill. Then on line 20, a slice of printer interface values are declared and initialized. The initialized slice is using value semantics on line 21 by storing a copy of the user value inside of index 0. Then on line 22, pointer semantics are used to store a copy of the user address inside of index 1.
On line 25, the user value is changed and finally on line 27, the slice is iterated over displaying the name for each user stored inside the respective interface value.
Figure 1 below shows how there are two distinct user values that exist. Index 0 references a copy (value semantics) of the original user value declared on line 18, and index 1 references the original value (pointer semantics) declared on line 18.
Figure 1
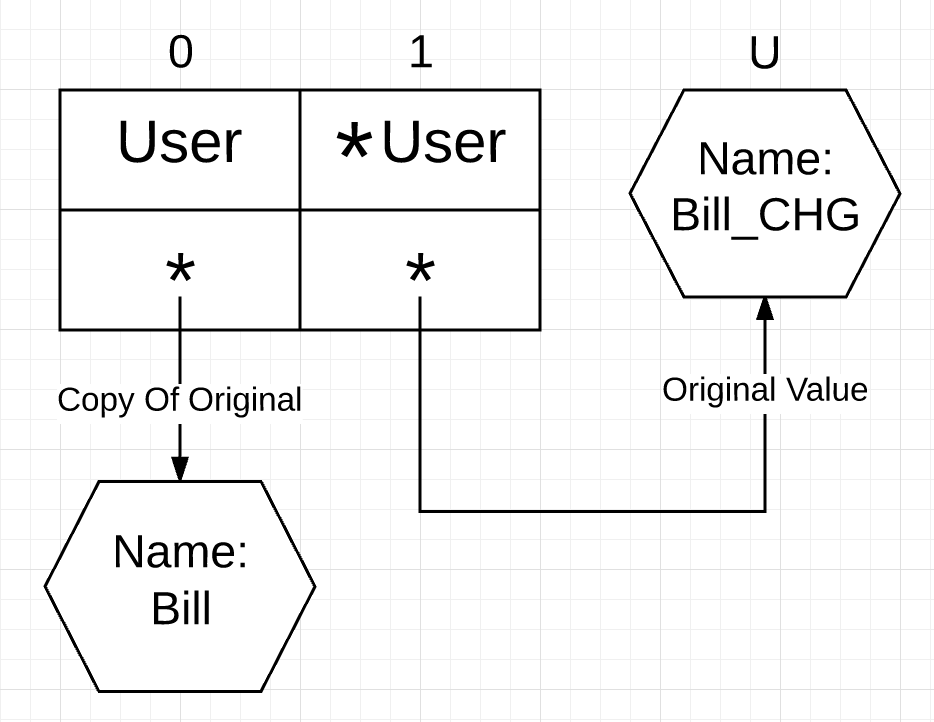
The final output shows that only index 1, the interface value using pointer semantics, sees the change.
Listing 2
User Name: Bill
User Name: Bill_CHG
This example provided the language mechanics for value/pointer semantics with interfaces, but there is more to learn.
Remember from the other posts I asked you to read, choosing one semantic over the other is a decision that is made at the time you are declaring or using a type. You want to maintain as much consistency with semantics as possible. This example we just went through is showing you how to apply the different semantics with interfaces.
Method Sets
Before moving beyond the value/pointer semantics provided with interfaces, It’s important to review the rules for method sets. Method set rules help describe when a piece of data of a given type can be stored inside of an interface. These rules are all about integrity.
Figure 2
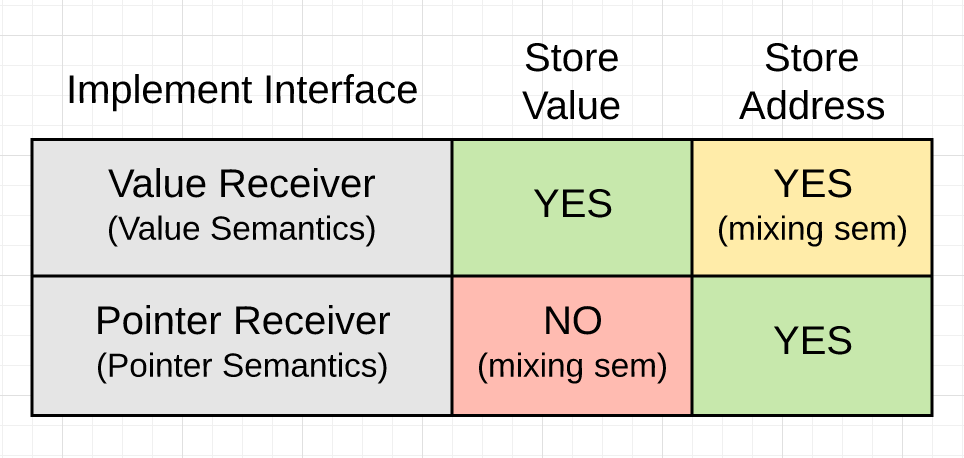
The rules state: when an interface is implemented using a value receiver (value semantics), copies of values and addresses can be stored inside the interface. However, when the interface is implemented using a pointer receiver (pointer semantics), only copies of addresses can be stored.
This begs the question – why not allow copies of values to be stored inside the interface when pointer semantics are being used? The answer is a two part integrity issue.
First, you can’t guarantee that every value is addressable. If you can’t take a value’s address, it can’t be shared and therefore a pointer receiver method can’t be used.
This next example shows how you can’t always take the address of a value in Go.
https://play.golang.org/p/mddefYbL09
Listing 3
01 package main
02
03 import "fmt"
04
05 type notifier interface {
06 notify()
07 }
08
09 type duration int
10
11 func (d *duration) notify() {
12 fmt.Println("Sending Notification in", *d)
13 }
14
15 func main() {
16 duration(42).notify()
17 }
In listing 3, a type named duration is declared and the notifier interface is implemented using pointer semantics on line 11. In the main function on line 16, the literal value of 42 is converted into a value of type duration and then the notify method is called. This call to the notify method causes the following compiler error:
Listing 3
main.go:16: cannot call pointer method on duration(42)
main.go:16: cannot take the address of duration(42)
Because literal values are constants in Go, they only exist at compile time and don’t have an address. The notify method requires the duration value to be shared, which is not possible. This explains the first reason why an interface that is implemented using pointer semantics only allows copies of addresses to be stored. The compiler can’t assume that it can take the address of any given value for a type that implemented the interface using pointer semantics.
The second reason is just as important, and I think it is a huge win for integrity. Look at the method set rule again for pointer semantics.
Figure 3

This part of the rule is preventing you from storing copies of values (value semantics) inside the interface if you implement the interface using pointer semantics. The rule enforces the idea that, if you change the semantic from pointer to value, it crosses a dangerous line. You can only share values with the interface and never store actual values if you implement the interface with a pointer receiver. You can never assume that it is safe to make a copy of any value that is pointed to by a pointer. This is why the “store value” box for pointer semantics is red.
Look at the method set rule again for value semantics:
Figure 4

This part of the rule is allowing you to store copies of values (value semantics) and addresses (pointer semantics) inside the interface if you implement the interface using value semantics. The rule supports the idea that if you change the semantic from value to pointer, it can be safe. However, there is a word of caution related to this idea. Mixing semantics is a consistency issue that must be performed as a conscious exception. Consistency is everything, and mixing semantics can create unexpected side effects in code. This is why the “store pointer” box for value semantics is yellow.
Interfaces Are Valueless
You might be thinking, since the second word of the interface value is always an address to the concrete value being stored inside it, there is always going to be an address that can be used to call the pointer receiver method. Why then would storing a value when pointer semantics are used to implement the interface be restricted?
The fact that the second word of the interface value stores an address is irrelevant. If you consider this implementation detail when defining the method set rules, you are essentially allowing implementation details to creep into the spec. From the specification point of view, how anything is implemented is irrelevant as the implementation is always changing.
In fact, in version 1.4 of Go, a change was made to the interface implementation:
https://golang.org/doc/go1.4#compatibility
“In earlier releases, the interface contained a word that was either a pointer or a one-word scalar value, depending on the type of the concrete object stored. This implementation was problematical for the garbage collector, so as of 1.4 interface values always hold a pointer.”
I want you to understand that interface values from our code perspective are “valueless”. There is nothing concrete about an interface value in and of itself.
This next example provides code to help explain this.
https://play.golang.org/p/bVzF-qSOtM
Listing 4
01 package main
02
03 import "fmt"
04
05 type notifier interface {
06 notify()
07 }
08
09 type duration int
10
11 func (d duration) notify() {
12 fmt.Println("Sending Notification in", d)
13 }
14
15 func main() {
16 var n notifier
17 n = duration(42)
18 n.notify()
19 }
In listing 4 on line 16, a variable named n of the interface type notifier is declared and set to its zero value, a nil interface value. The variable n is valueless, and not until line 17 does the interface value have any concrete state.
The only thing that makes an interface concrete is the data that is stored inside of it. The method set rules define what data (values or addresses) can be stored based on how the method set was implemented (using value or pointer semantics). Integrity and semantics are what define the rules. How all that is physically done is an implementation detail.
To really bring this home. When two interface values are compared, it’s the concrete data inside of them and not the interface values themselves that are compared.
https://play.golang.org/p/Hk7FuovsTH
Listing 5
01 package main
02
03 import "fmt"
04
05 type errorString struct {
06 s string
07 }
08
09 func (e errorString) Error() string {
10 return e.s
11 }
12
13 func New(text string) error {
14 return errorString{text}
15 }
16
17 var ErrBadRequest = New("Bad Request")
18
19 func main() {
20 err := webCall()
21 if err == ErrBadRequest {
22 fmt.Println("Interface Values MATCH")
23 }
24 }
25
27 func webCall() error {
28 return New("Bad Request")
29 }
In listing 5 on lines 05 through 15, I copied the implementation of the default error type in Go from the errors package with one change. My implementation of the New function on line 13 is using value semantics instead of pointer semantics. It stores an errorString value inside the error interface value being returned and not its address.
On line 17, an error interface variable is declared for the “Bad Request” error. Skipping to line 27, the webCall function is returning a new error interface value with the same message “Bad Request”. Then in the main function on line 19, the webCall function is called and the returned error interface value is compared with the error interface variable.
When you run this program you will see that both error interface values are equivalent.
Listing 6
Interface Values MATCH
Different error interface values with the same concrete data stored inside of them will always be equivalent. The data inside the interface is what is being compared, not the interface itself. When using pointer semantics, addresses are being compared. When using value semantics, values are being compared. Interface values are valueless and it’s always about the concrete data stored inside of them.
Conclusion
This post presents another example of how value and pointer semantics play a significant role in writing code in Go. The interface can store its own copy of a value (value semantics) or a copy of the value’s address (pointer semantics). I wanted to show how the method set rules are providing a level of integrity checking by not allowing a change in semantic from pointer to value. This promotes the idea that it is not safe to make a copy of the value that is pointed to by a pointer. This mix of semantic must be taken seriously.
As you continue to write code in Go, look at the semantics you are using for any given type. During code reviews, look for consistency in semantic for data of a given type and question code that violates it. There are exceptions to every rule, but I want to make sure that the exceptions are happening as a conscious choice.



